I have a pandas dataframe similar to the one below. It contains 3 identifiers broken into corresponding months (length can vary), their corresponding values and boolean flags. For each identifier, I will need to take the values until the first '1' is seen (inclusive), along with the other variables. If all the flags are '0' then it'll take all the rows for that id.
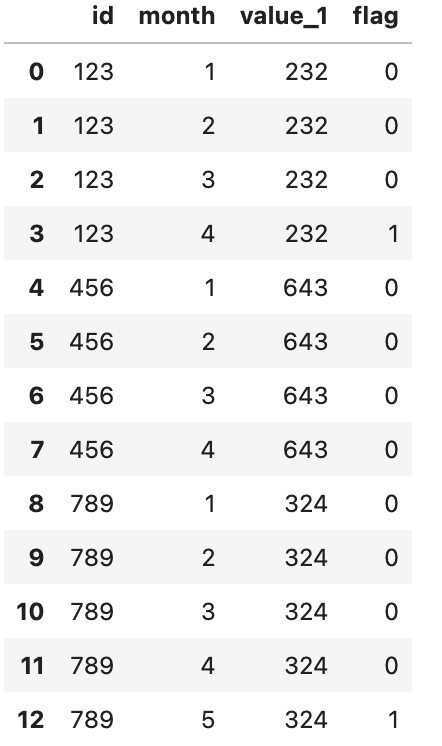
The desired output is shown in the image below.
data = {'id':['123', '123', '123', '123', '123', '456', '456', '456', '456', '789', '789', '789', '789', '789', '789'],
'month':[1,2,3,4,5,1,2,3,4,1,2,3,4,5,6],
'value_1': [232,432,556,223,643,556,121,853,343,324,654,765,128,543,776],
'flag':[0,0,0,1,1,0,0,0,0,0,0,0,0,1,1]}
# Create DataFrame
d = pd.DataFrame(data)
I have tried using groupby for the transformation (shown below). For the value column I'm only concerned with the first value. However, I would like to have all the months in the same order which does not seem to be possible with this approach.
temp = d['flag'].ne(1).cumsum()
grouped = d.groupby(temp).agg({'id': 'first',
'value_1': 'first',
'flag': lambda x: max(x)})
CodePudding user response:
IIUC, try:
output = d[d.groupby("id")["flag"].transform(lambda x: x.shift().fillna(0).cumsum())==0]
output["value_1"] = output.groupby("id")["value_1"].transform("first")
>>> output
id month value_1 flag
0 123 1 232 0
1 123 2 232 0
2 123 3 232 0
3 123 4 232 1
5 456 1 556 0
6 456 2 556 0
7 456 3 556 0
8 456 4 556 0
9 789 1 324 0
10 789 2 324 0
11 789 3 324 0
12 789 4 324 0
13 789 5 324 1