I am trying to take my dataframe and delete each row, corresponding to values in another row, based on whether or not each category of rows contains a value exceeding a threshold. While I feel this should be a simple "if" conditional statement, I am confused over whether this is actually as simple as I think it might be, or if this is much more complex. I am using python and pandas. I will demonstrate with an example below to better communicate this problem.
I have the following dataframe:
Date Category Value
---------------------------------------
2015-06-02 1 2
2015-06-03 1 9
2015-06-04 1 2
2015-06-05 2 2
2015-06-06 2 8
2015-06-07 2 11
2015-06-08 2 2
2015-06-09 4 2
2015-06-10 4 5
2015-06-11 4 12
2015-06-12 4 2
2015-06-13 6 2
2015-06-14 6 8
2015-06-15 6 2
2015-06-16 8 2
2015-06-17 8 6
2015-06-18 8 10
2015-06-19 8 2
As you can see, rows are categorized by a certain ID corresponding to the "Category" column. So in this example there are 5 "Categories": "1", "2", "4", "6", "8". It does not matter that they do not increase by 1 for each category, so long as the categories are kept distinct. And so, you will see a patter, given that this is date chronological data, for each category, the value starts at 2, has some values in between, however many, and ends at 2. So each category has values "in between" values of 2. What I want to do is take the dataframe and remove the categories where between the two values of 2, for that unique category, where there no value that is >= 10. As you can see, this would mean removing Category 1 (it has a 9 between the 2's), and removing Category 6 (it has an 8 between the 2's). Of course, there can be any number of values in between the 2's, but at least one of them must be >= 10 And so I would want to produce the following dataframe:
Date Category Value
---------------------------------------
2015-06-05 2 2
2015-06-06 2 8
2015-06-07 2 11
2015-06-08 2 2
2015-06-09 4 2
2015-06-10 4 5
2015-06-11 4 12
2015-06-12 4 2
2015-06-16 8 2
2015-06-17 8 6
2015-06-18 8 10
2015-06-19 8 2
How can this be done in python? While I would think I would write a conditional statement that says "if value in df['Value'] < 10, then remove", but I am not sure how to organize this based on the "Category" column like I mentioned.
CodePudding user response:
Since the groups start/end with 2/3, the condition df['Value'].ge(10) already search for those rows in the middle. You only need to do groupby().transform('any') on that condition:
mask = df['Value'].ge(10).groupby(df['Category']).transform('any')
df[mask]
Output:
Date Category Value
3 2015-06-05 2 3
4 2015-06-06 2 8
5 2015-06-07 2 11
6 2015-06-08 2 3
7 2015-06-09 4 3
8 2015-06-10 4 5
9 2015-06-11 4 12
10 2015-06-12 4 3
14 2015-06-16 8 3
15 2015-06-17 8 6
16 2015-06-18 8 10
17 2015-06-19 8 3
CodePudding user response:
The groupby in pandas can be used as an iterator that returns subsetted dataframes so that operations can be done on each sub-dataframe. Take this example:
cats = reduce(lambda x, y: x y, [[i]*4 for i in range(4)])
vals = [random.randint(0, 20) for _ in range(len(cats))]
df = pd.DataFrame({"category": cats, "values": vals})
This random dataframe can look like this:
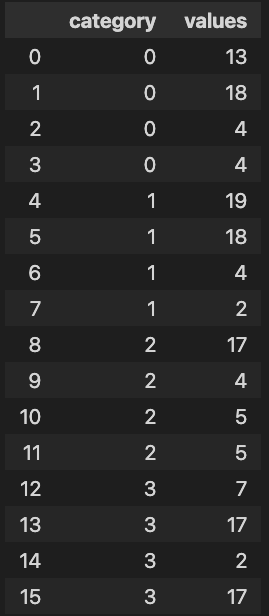
You can then iterate over and apply logic specifically to each sub-category like this:
res = []
for _, sub_df in df.groupby("category"):
if sub_df["values"].max() >= 10:
res.append(sub_df)
if res:
df = pd.concat(res)
This code looks at each subset and then appends it to a list if it meets the criteria. This list of dataframes (if not empty) then is concatenated into one dataframe. Note: the order here will now be ordered by the grouped variable. If this bugs you then just used df.sort_index() to re-sort it by original index.