I have the payments table and it happens that payments could be submitted erroneously, so for my analysis purposes, I need to remove the negated amount and the actual payment (it is the payment submitted prior to the negated amount). However, it is not necessary that the negative amount proceeds the positive one.
Use case 1: Original table:
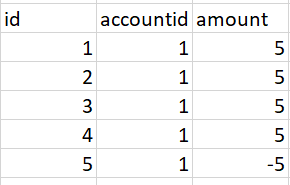
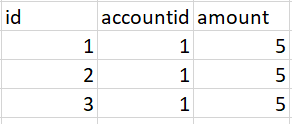
Expected outcome:
However, I also have the cases like the below when several payments were done erroneously: Use case 2: Original table. Although, I am almost ready to give up on these use cases.
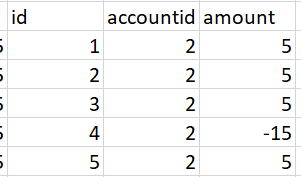
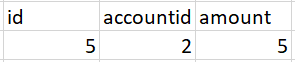
Expected outcome:
I tried to resolve it on the SQL level but it seems to be a daunting task for SQL. All SQL solutions I tried, take the modulus of the amount and then, do several groups on accountid and the abs value, and I feel it is the right direction but then, maybe there is a better way to do it in the Python world.
import numpy as np
import pandas as pd
data = {
'id': ['1','2','3','4','5','6','7','8','9','10'],
'accountid': ['1','1','1','1','1','2','2','2','2','2'],
'amount': [5,5,5,5,-5,5,5,5,-15,5]
}
df = pd.DataFrame(data)
CodePudding user response:
import numpy as np
import pandas as pd
data = {
'id': ['1','2','3','4','5','6','7','8','9','10'],
'accountid': ['1','1','1','1','1','2','2','2','2','2'],
'amount': [5,5,5,5,-5,5,5,5,-15,5]
}
df = pd.DataFrame(data)
def clean_df(df):
df = df.copy()
result = []
g = df.groupby("accountid")
for _, group in g:
to_reduce = group[group.amount < 0].amount.abs().sum()
to_drop = []
group = group[group.amount > 0]
for index, row in group[::-1].iterrows():
if to_reduce > 0:
amount = row.amount
to_reduce -= amount
to_drop.append(index)
if to_reduce == 0:
group = group.drop(to_drop)
result.append(group)
break
return pd.concat(result)
clean_df(df)
# output
id accountid amount
0 1 1 5
1 2 1 5
2 3 1 5
5 6 2 5
Case when we have accountid == 2 only:
id accountid amount
0 1 2 5
1 2 2 5
2 3 2 5
3 4 2 -15
4 5 2 5
clean_df(df)
# oudput
id accountid amount
0 1 2 5
CodePudding user response:
You can use this for the first case, the second case is not clear to me.
import pandas as pd
import numpy as np
In [54]: df[~np.logical_or(df.amount.lt(0).shift(-1).fillna(False), df.amount.lt(0))]
Out[54]:
id accountid amount
0 1 1 5
1 2 1 5
2 3 1 5
CodePudding user response:
I was able to get to your desired outcome by creating two temporary helping columns, and dropping some rows with conditions. Having complicated loops is rarely a good idea in my opinion as pandas is well equipped.
Adding two columns, the total amount of each 'accountid', groupby.sum() and the cumulative sum of 'amount' column, groupby.cumsum():
t = df.groupby('accountid',as_index=False).amount.sum().rename({'amount':'total_amount'},axis=1)
df = pd.merge(df,t,on='accountid',how='left')
df['cumsum_id'] = df.groupby('accountid')['amount'].cumsum()
>>> df
id accountid amount total_amount cumsum_id
0 1 1 5 15 5
1 2 1 5 15 10
2 3 1 5 15 15
3 4 1 5 15 20
4 5 1 -5 15 15
5 6 2 5 5 5
6 7 2 5 5 10
7 8 2 5 5 15
8 9 2 -15 5 0
9 10 2 5 5 5
Then the last step would be to drop the rows where the 'total_amount' of each 'accountid' is greater than or equal to the cumulative sum of each 'accountid', and where the 'amount' col is greater than 0. Lastly, dropping the duplicates:
df[(df['total_amount'] >= df['cumsum_id']) & (df['amount'] > (0))].drop_duplicates(subset=['accountid','amount','total_amount','cumsum_id']).drop(['total_amount','cumsum_id'],axis=1)
Result
id accountid amount
0 1 1 5
1 2 1 5
2 3 1 5
5 6 2 5