I extracted some gambling data from online and exported to Excel. Now trying to clean up a few columns.
The spread for each team was pulled into the same column. I am able to extract each one except the whole numbers.
Code:
df['Away Spread'] = df['Open'].str.extract(pat= '([- A-Z].[^-/ ].[0-9]?)').fillna(df['Open'].str[0:2])
Output:
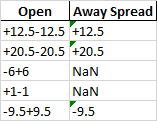
Desired Output:
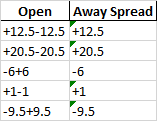
Best Output:
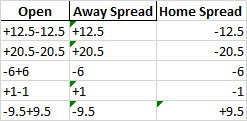
If the best output can't be accomplished in one line, please don't tell me. I should be able to convert 'Away Spread' to float and then make 'Home Spread' the opposite. I just can't help feeling I missed something in my regex pattern.
Thanks to all who take a look!
CodePudding user response:
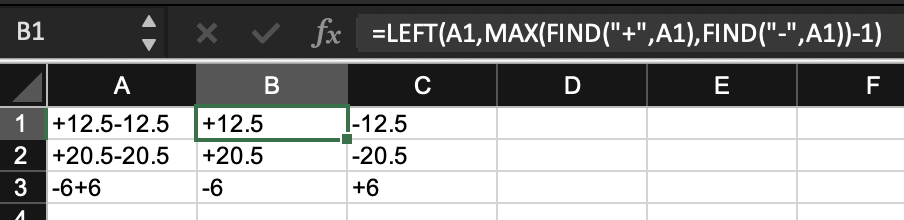
You can do this directly in Excel by finding the second instance of or -
First half
=LEFT(A1,MAX(FIND(" ",A1),FIND("-",A1))-1)
Second half
=RIGHT(A1,LEN(A1)-LEN(B1))
CodePudding user response:
You can use
df['Away Spread'] = df['Open'].str.extract(r'([- ]?\d*\.?\d )', expand=False).fillna(df['Open'].str[0:2])
Notes:
.extract(r'([- ]?\d*\.?\d )', expand=False)- extracts the first positive or negative float/integer number (expand=Falsewill make sure the result is a series, not a df).fillna(df['Open'].str[0:2])will fill the values where no match occurred with the first two chars of the values from theOpencolumn.
See the regex demo (I added ^ to only match at the start of the lines , see also m flag).