I am working with numpy and pandas on Python to learn how to work on dataframes. I'm coding on Collaboratory and I have loaded the Iris dataset but for some reason, there is no "Species" collumn in my dataframe. Maybe I've loaded it in an incorrect fashion? I'd appreciate help on the matter.
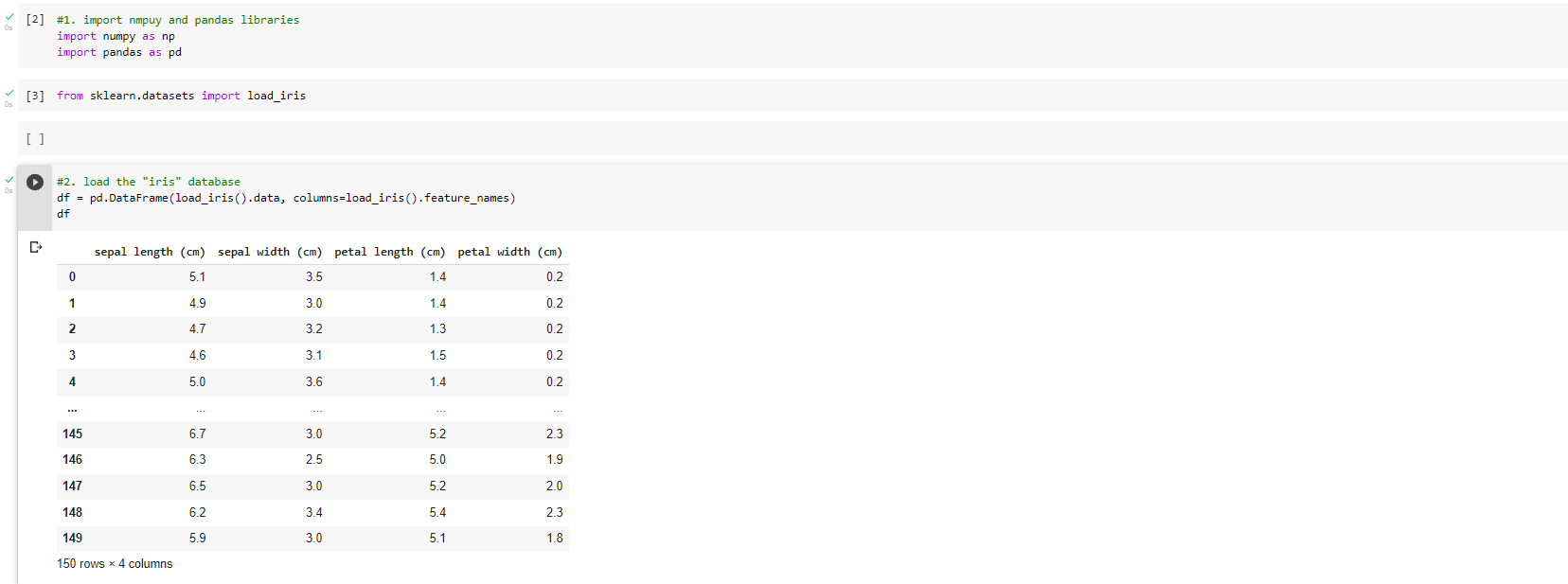
I added an image, if the code is still needed then this is what I have:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
df = pd.DataFrame(load_iris().data, columns=load_iris().feature_names)
CodePudding user response:
Try:
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(data=np.c_[iris['data'], iris['target']],
columns= iris['feature_names'] ['target']).astype({'target': int}) \
.assign(species=lambda x: x['target'].map(dict(enumerate(iris['target_names']))))
Output:
>>> df
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) target species
0 5.1 3.5 1.4 0.2 0 setosa
1 4.9 3.0 1.4 0.2 0 setosa
2 4.7 3.2 1.3 0.2 0 setosa
3 4.6 3.1 1.5 0.2 0 setosa
4 5.0 3.6 1.4 0.2 0 setosa
.. ... ... ... ... ... ...
145 6.7 3.0 5.2 2.3 2 virginica
146 6.3 2.5 5.0 1.9 2 virginica
147 6.5 3.0 5.2 2.0 2 virginica
148 6.2 3.4 5.4 2.3 2 virginica
149 5.9 3.0 5.1 1.8 2 virginica
[150 rows x 6 columns]