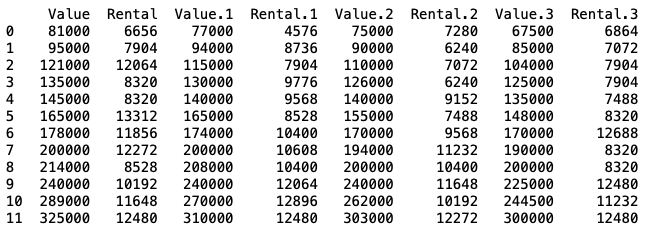
I have a dataframe read into from an Excel file. I would like to combine all 4 "Value" columns and "Rental" Columns into a respective single column containing all values so that I have one Value and one Rental column.
Current dataframe is shown below.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_excel('HW2_Data.xlsx', sheet_name='Problem 4')
print(df)
CodePudding user response:
Try using pd.wide_to_long:
#Create dummy dataframe matching your column headers
df = pd.concat(
[
pd.DataFrame(
{
f"Value{i}": sorted(np.random.randint(75, 350, 12) * 1000),
f"Rental{i}": sorted(np.random.randint(4370, 13000, 12)),
}
)
for i in ["", ".1", ".2", ".3"]
],
axis=1,
)
#Rename column headers to get consistent <word>.<number> format by adding .0 to first two columns
dfm = df.rename(columns=lambda x: x if '.' in x else x '.0')
# Use pd.wide_to_long
df_out = pd.wide_to_long(dfm.reset_index(), ['Value', 'Rental'], 'index', 'No', '.', '\d')
df_out
Output:
Value Rental
index No
0 0 89000 4492
1 0 151000 4799
2 0 175000 4849
3 0 187000 4853
4 0 254000 5301
5 0 271000 5590
6 0 279000 5860
7 0 297000 7653
8 0 297000 10308
9 0 299000 10604
10 0 330000 10695
11 0 337000 12167
0 1 87000 4482
1 1 91000 5598
2 1 145000 7225
3 1 157000 8105
4 1 185000 8558
5 1 192000 8700
6 1 193000 9109
7 1 215000 9437
8 1 250000 10963
9 1 260000 11362
10 1 276000 11895
11 1 338000 12079
0 2 84000 5141
1 2 92000 5198
2 2 107000 5646
3 2 136000 6417
4 2 143000 8548
5 2 200000 9338
6 2 225000 9679
7 2 245000 9997
8 2 327000 11787
9 2 328000 11829
10 2 328000 11889
11 2 334000 12438
0 3 81000 4652
1 3 112000 5129
2 3 143000 5648
3 3 153000 6412
4 3 178000 6629
5 3 188000 7463
6 3 239000 9382
7 3 240000 9594
8 3 263000 10505
9 3 265000 11633
10 3 296000 11835
11 3 314000 12416
CodePudding user response:
Okay, so I originally wanted to see if it was possible to prevent your data from being loaded in such an unfortunate format in the first place, but I've been waiting for an hour now and I'm ready for bed. Here's one way you could fix your issue which would not require looping:
df = df.rename(columns={"Value": "Value.0", "Rental": "Rental.0"})
pd.wide_to_long(df.reset_index(), stubnames=["Value", "Rental"], i="index", j="drop", suffix=".\d ").reset_index().drop(["index", "drop"], axis=1)