Using the following code I was able to map a list of dictionaries by a key
import json
values_list = [{"id" : 1, "user":"Rick", "title":"More JQ"}, {"id" : 2, "user":"Steve", "title":"Beyond"}, {"id" : 1, "user":"Rick", "title":"Winning"}]
result = {}
for data in values_list:
id = data['id']
user = data['user']
title = data['title']
if id not in result:
result[id] = {
'id' : id,
'user' : user,
'books' : {'titles' : []}
}
result[id]['books']['titles'].append(title)
print(json.dumps((list(result.values())), indent=4))
Knowing how clean is Jolt Spec and trying to separate the schema outside of the code. Is there a way to use Jolt Spec to achieve the same result.
The Result
[
{
"id": 1,
"user": "Rick",
"books": {
"titles": [
"More JQ",
"Winning"
]
}
},
{
"id": 2,
"user": "Steve",
"books": {
"titles": [
"Beyond"
]
}
}
]
CodePudding user response:
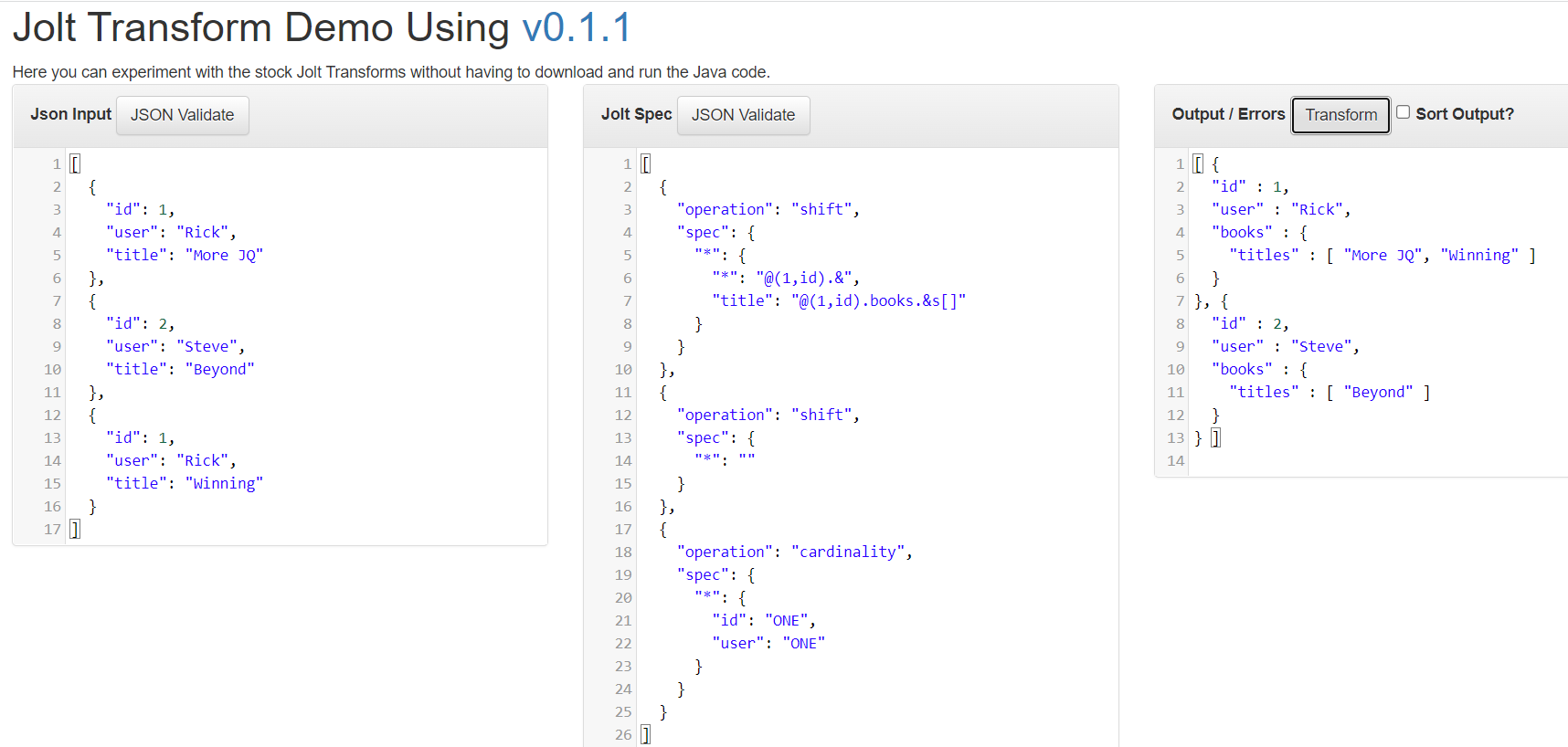
You can use three levels of consecutive specs
[
{
"operation": "shift",
"spec": {
"*": {
"*": "@(1,id).&",
"title": "@(1,id).books.&s[]"
}
}
},
{
"operation": "shift",
"spec": {
"*": ""
}
},
{
"operation": "cardinality",
"spec": {
"*": {
"id": "ONE",
"user": "ONE"
}
}
}
]
- in the first spec, the common
idvalues are combined by"@(1,id)."expression - in the second spec, the integer keys(
1,2) of the outermost objects are removed - in the last spec,only the first of the repeating elements are picked