I am trying to scrape external data to pre-fill form data on a website. The aim is to find a keyword, and return the class name of the element that contains that keyword. I have the constraints of not knowing if the website does have the keyword or what type of tag the keyword is within.
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
chromeDriverPath = "./chromedriver"
chrome_options = webdriver.ChromeOptions()
driver = webdriver.Chrome(chromeDriverPath, options=options)
driver.get("https://www.scrapethissite.com/pages/")
#keywords to scrape for
listOfKeywords = ['ajax', 'click']
for keyword in listOfKeywords:
try:
foundKeyword = driver.find_element(By.XPATH, "//*[contains(text(), " keyword ")]")
print(foundKeyword.get_attribute("class"))
except:
pass
driver.close()
This example returns the highest parent, not the immediate parent. To elaborate this example prints "" because it is trying to return the class attribute for the <html> tag which does not have a class attribute. Similarly if I changed the code to search for the keyword in a <div>
foundKeyword = driver.find_element(By.XPATH, "//div[contains(text(), " keyword ")]")
This prints "container", for both 'ajax' and 'click' because the div class='container' wraps everything on the website.
So the answer I want for the above example is, for the keyword 'ajax', it should print 'page-title' (the class of the immediate parent tag). Similarly, for 'click', I would expect it to print 'lead session-desc'.
The below image may help to visualize this
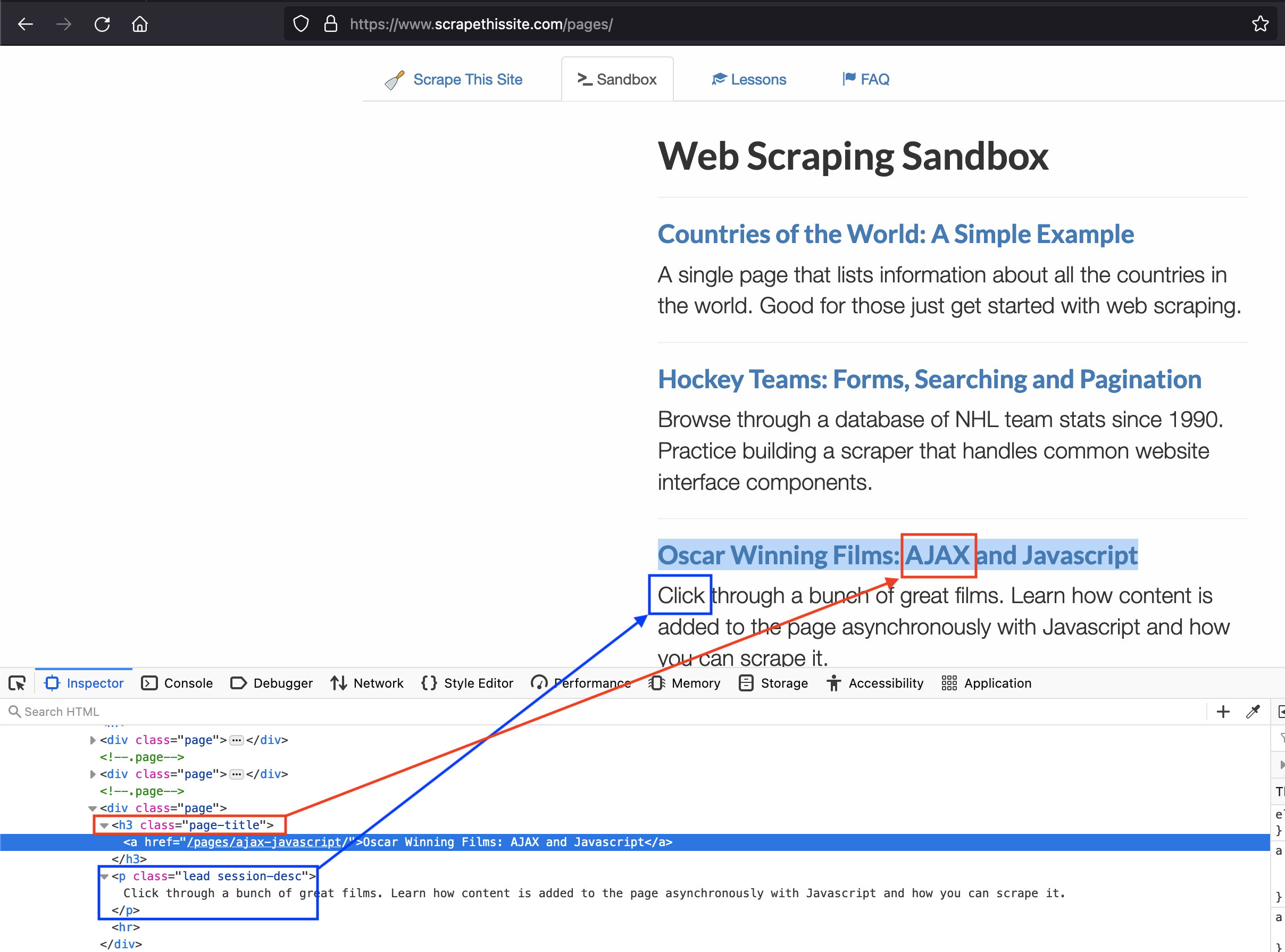
CodePudding user response:
As per the comments to get the parent element of an webelement, can use parent keyword in the xpath.
<p> is text node. The parent tag for that element is <div class='page'>
Try like below:
driver.get("https://www.scrapethissite.com/pages/")
listOfKeywords = ['AJAX', 'Click']
for keyword in listOfKeywords:
try:
element = driver.find_element_by_xpath("//*[contains(text(),'{}')]".format(keyword))
parent = element.find_element_by_xpath("./parent::*").get_attribute("class")
tag_class = element.get_attribute("class")
print(f"{keyword} : Parent tag class - {parent}, tag class-name - {tag_class}")
except:
print("Keyword not found")
AJAX : Parent tag class - page-title, tag class-name -
Click : Parent tag class - page, tag class-name - lead session-desc
CodePudding user response:
There are two distinct cases as follows:
- In the first case you can opt to lookout for the keywords in the headings which have a parent
<h3>tag with classpage-title - In the second case you can lookout for the keywords in the
<p>tags which have a sibling<h3>tag with classpage-title.
For the first usecase to lookout for keywords like AJAX, you can use the following Locator Strategies:
driver.get("https://www.scrapethissite.com/pages/")
listOfKeywords = ['AJAX', 'Ajax']
for keyword in listOfKeywords:
try:
print(WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//a[contains(., '{}')]//parent::h3[1]".format(keyword)))).get_attribute("class"))
except:
pass
driver.quit()
For the second usecase to lookout for keywords like Click, you can use the following Locator Strategies:
driver.get("https://www.scrapethissite.com/pages/")
listOfKeywords = ['Click', 'click']
for keyword in listOfKeywords:
try:
print(WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//p[contains(., '{}')]//preceding::h3[1]".format(keyword)))).get_attribute("class"))
except:
pass
driver.quit()
In both the cases, the console output will be:
page-title
Update
Combining both the usecase in a single one you can use the following solution:
driver.get("https://www.scrapethissite.com/pages/")
listOfKeywords = ['AJAX', 'Click']
for keyword in listOfKeywords:
try:
print(WebDriverWait(driver, 5).until(EC.visibility_of_element_located((By.XPATH, "//*[contains(., '{}')]//parent::h3[1]".format(keyword)))).get_attribute("class"))
except:
pass
driver.quit()
Console Output:
page-title
page-title