I have a problem, this is my df
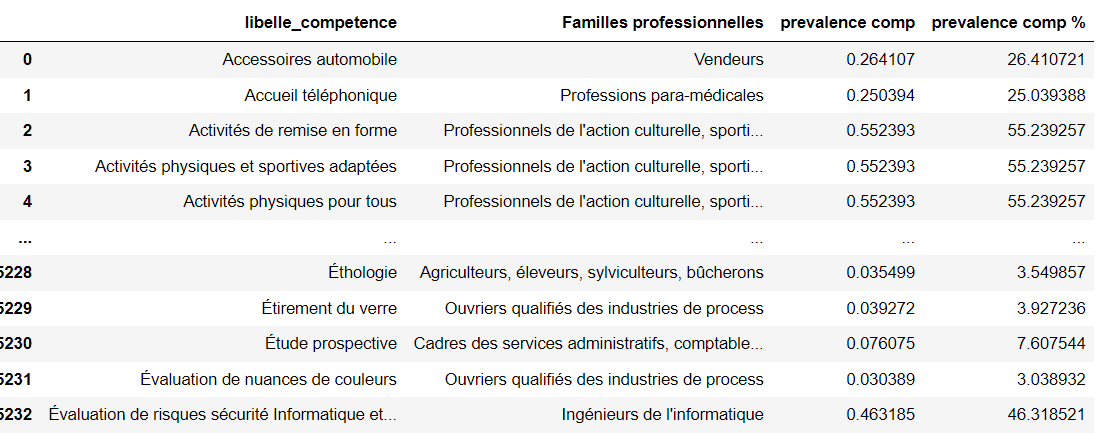
{'libelle_competence': {0: 'Accessoires automobile',
1: 'Accueil téléphonique',
2: 'Activités de remise en forme',
3: 'Activités physiques et sportives adaptées',
4: 'Activités physiques pour tous'},
'Familles professionnelles': {0: ' Vendeurs',
1: ' Professions para-médicales',
2: " Professionnels de l'action culturelle, sportive et surveillants",
3: " Professionnels de l'action culturelle, sportive et surveillants",
4: " Professionnels de l'action culturelle, sportive et surveillants"},
'prevalence comp': {0: 0.264107210349354,
1: 0.25039387926072904,
2: 0.5523925685283885,
3: 0.5523925685283885,
4: 0.5523925685283885},
'prevalence comp %': {0: 26.410721034935314,
1: 25.03938792607282,
2: 55.23925685283866,
3: 55.23925685283866,
4: 55.23925685283866}}
I want to group by Familles professionnelles and libelle_competence and to add to sort the prevalence % column with nlargest(10) (only to keep the 10 first libelle competence)
df.groupby(["Familles professionnelles","libelle_competence"])["prevalence comp %"].nlargest(10)
but this is not what I want.
Edit : What I show is basically a head of my dataframe to dict. Here is what my df looks like:
the idea is to plot a graph for each 'famille professionnelles' when I keep only the top 10 libelle_competence that correspond to prevalence comp % . Is it better ?
CodePudding user response:
groupby will make pandas execute the following function for all groups. In your case, you want to discard a part of your 'libelle_competence'-values. Therefore you should not put them into the groupby.
Using nlargest will absolutely work. If you want to keep the other columns though, you need to do a bit of formatting. I did something like this (using only the top 2 values so that something would get filtered :D)
In [14]: df.groupby('Familles professionnelles').apply(lambda x: x.nlargest(2, 'prevalence comp %')).drop('Familles professionnelles', axis=1).reset_index(level=1, drop=True)
Out[14]:
libelle_competence prevalence comp prevalence comp %
Familles professionnelles
Professionnels de l'a... Activités de remise e... 0.5524 55.2393
Professionnels de l'a... Activités physiques e... 0.5524 55.2393
Professions para-médi... Accueil téléphonique 0.2504 25.0394
Vendeurs Accessoires automobile 0.2641 26.4107
Is this what you want?