I have a dataframe which contains two columns. One of the columns named 'steps' begins with single digit numbers. I wish to keep only those rows which contain the maximum value for each sequence. It will be clear with this example: Consider the Dataframe 1 (as shown in figure), the sequences of first digit are as follows:
- 1
- 1 2 3 4
- 1 2 3
- 1 2
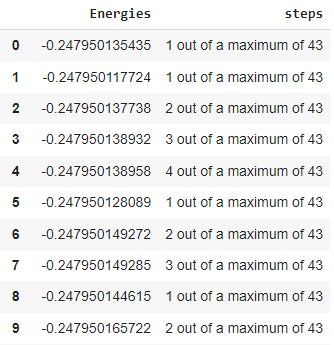
Hence, I just want to keep the row number 0, 4, 7, and 9. Because they contain the highest first digit under the column - 'steps' for each sequence.
Any help in this regard would be helpful. Here is the code to generate the dataframe, 'Energies' column is irrelevant:
copy = pd.DataFrame([(234, 1), (234, 1), (234, 2), (234, 3), (234, 4), (234, 1), (234, 2),
(234, 3), (234, 1), (234, 2)], columns=['Energies', 'steps'])
CodePudding user response:
Use a boolean mask:
>>> copy[copy['steps'].ge(copy['steps'].shift(-1, fill_value=-np.inf))]
Energies steps
0 234 1
4 234 4
7 234 3
9 234 2