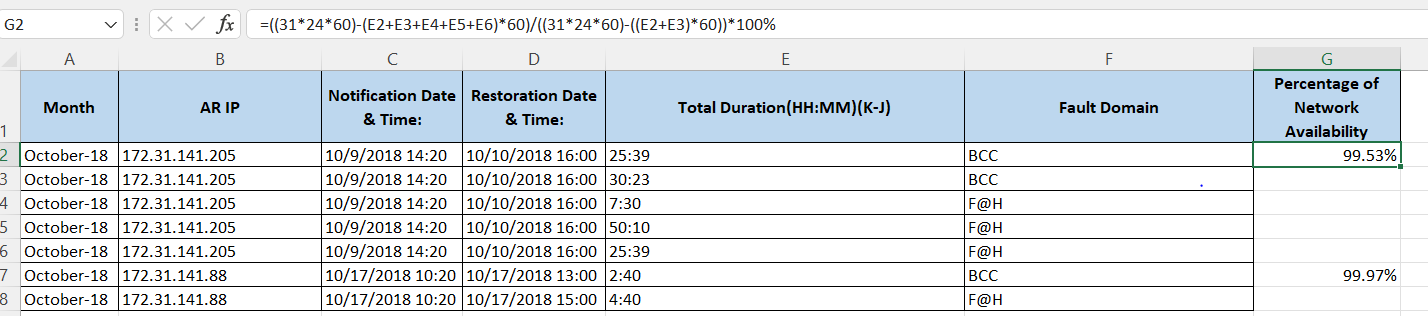
Here i calculated Percentage of Network Availability Using following formula in excel for 172.31.141.205 :
First one : ((31 * 24 * 60)-(E2 E3 E4 E5 E6)*60) / (((31 * 24 * 60)-((E2 E3) * 60)) * 100%
above i subtract all 'Total duration' * 60 from (31 * 24 * 60) and divide this ((31 * 24 * 60)-((E2 E3) * 60)) here (E2 E3) is subtracted because 'Fault Domain" entry is BCC.
- Another one formula for 172.31.141.88 :
(((31 * 24 * 60)-(E7 E8) * 60) / (((31 * 24 * 60)-(( E7) * 60)) * 100%
above i subtract all 'Total duration' * 60 from (31 * 24 * 60) and divide this (((31 * 24 * 60)-(E7) * 60)) here (E7) is subtracted because 'Fault Domain" entry is BCC.
Is their any universal logic for duplicate rows to calculate Percentage of Network availability using 'Total Duration' and conditions on 'Fault Domain' ?
Please kindly check the snapshot for better understand
CodePudding user response:
You can use locking logic in excel. Moreover try not to write length syntax. it makes reading unclear.
The locking logic: ((31 * 24 * 60)-SUM($E$2:$E$6)*60) / (((31 * 24 * 60)-(($E$2 $E$3) * 60)) * 100%
And once the output is generated then reference it to the cell where you want the same output with the help of =
CodePudding user response:
import pandas as pd
AR_IP = ["172.31.141.205","172.31.141.205","172.31.141.205","172.31.141.205","172.31.141.205",
"172.31.141.88","172.31.141.88"]
notifi_date = ["10/9/2018 14:20","10/9/2018 14:20","10/9/2018 14:20","10/9/2018 14:20",
"10/9/2018 14:20","10/17/2018 10:20","10/17/2018 10:20"]
rest_date = ["10/10/2018 16:00","10/10/2018 16:00","10/10/2018 16:00","10/10/2018 16:00",
"10/10/2018 16:00","10/17/2018 13:00","10/17/2018 15:00"]
duration = ["25:39","30:23","7:30","50:10","25:39","2:40","4:40"]
fault_domain = ["BCC","BCC","F@H","F@H","F@H","BCC","F@H"]
df = pd.DataFrame({
'ar_ip' : AR_IP,
'notifi_date' : notifi_date,
'rest_date' :rest_date,
"duration":duration,
'fault_domain':fault_domain
})
df['duration'] = df.duration.map(lambda x : int(str(x).split(':')[0])*60 int(str(x).split(':')[1]))
all_duration = (31 * 24 * 60 )
# Group with only BCC
bcc_faulted_duration = df[df['fault_domain']=='BCC'].groupby(by=['ar_ip']).sum()
# Group with all faults
all_faulted_duration = df.groupby(by='ar_ip').sum()
# Using your formula
# (all_duration - faulted_duration) / (all_duration - bcc_faulted_duration) * 100
perc_nw_avail = (all_duration - all_faulted_duration) / (all_duration - bcc_faulted_duration) * 100
Just that am not getting your formula correct ... But guess you wanted to implement in python ... You could get started with this .