I have a column in pandas dataframe that contains two types of information = 1. date and time, 2=company name. I have to split the column into two (date_time, full_company_name). Firstly I tried to split the columns based on character count (first 19 one column, the rest to other column) but then I realized that sometimes the date is missing so the split might not work. Then I tried using regex but I cant seem to extract it correctly.
The column:
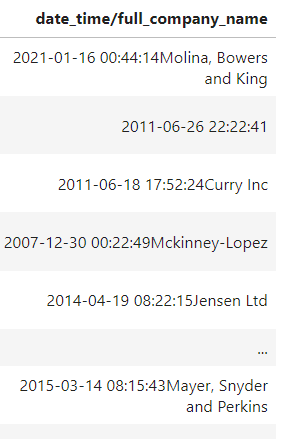
the desired output:
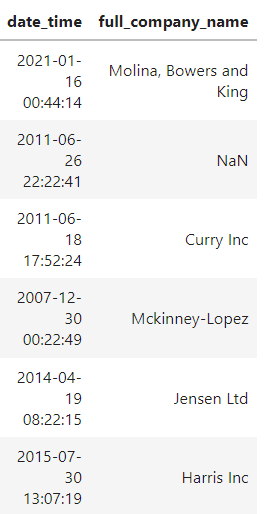
CodePudding user response:
If the dates are all properly formatted, maybe you don't have to use regex
df = pd.DataFrame({"A": ["2021-01-01 05:00:00Acme Industries",
"2021-01-01 06:00:00Acme LLC"]})
df["date"] = pd.to_datetime(df.A.str[:19])
df["company"] = df.A.str[19:]
df
# A date company
# 0 2021-01-01 05:00:00Acme Industries 2021-01-01 05:00:00 Acme Industries
# 1 2021-01-01 06:00:00Acme LLC 2021-01-01 06:00:00 Acme LLC
OR
df.A.str.extract("(\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2})(.*)")
CodePudding user response:
Note: If you have an option to avoid concatenating those strings to begin with, please do so. This is not a healthy habit.
Solution (not that pretty gets the job done):
import pandas as pd
from datetime import datetime
import re
df = pd.DataFrame()
# creating a list of companies
companies = ['Google', 'Apple', 'Microsoft', 'Facebook', 'Amazon', 'IBM',
'Oracle', 'Intel', 'Yahoo', 'Alphabet']
# creating a list of random datetime objects
dates = [datetime(year=2000 i, month=1, day=1) for i in range(10)]
# creating the column named 'date_time/full_company_name'
df['date_time/full_company_name'] = [f'{str(dates[i])}{companies[i]}' for i in range(len(companies))]
# Before:
# date_time/full_company_name
# 2000-01-01 00:00:00Google
# 2001-01-01 00:00:00Apple
# 2002-01-01 00:00:00Microsoft
# 2003-01-01 00:00:00Facebook
# 2004-01-01 00:00:00Amazon
# 2005-01-01 00:00:00IBM
# 2006-01-01 00:00:00Oracle
# 2007-01-01 00:00:00Intel
# 2008-01-01 00:00:00Yahoo
# 2009-01-01 00:00:00Alphabet
new_rows = []
for row in df['date_time/full_company_name']:
# extract the date_time from the row using regex
date_time = re.search(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', row)
# handle case of empty date_time
date_time = date_time.group() if date_time else ''
# extract the company name from the row from where the date_time ends
company_name = row[len(date_time):]
# create a new row with the extracted date_time and company_name
new_rows.append([date_time, company_name])
# drop the column 'date_time/full_company_name'
df = df.drop(columns=['date_time/full_company_name'])
# add the new columns to the dataframe: 'date_time' and 'company_name'
df['date_time'] = [row[0] for row in new_rows]
df['company_name'] = [row[1] for row in new_rows]
# After:
# date_time full_company_name
# 2000-01-01 00:00:00 Google
# 2001-01-01 00:00:00 Apple
# 2002-01-01 00:00:00 Microsoft
# 2003-01-01 00:00:00 Facebook
# 2004-01-01 00:00:00 Amazon
# 2005-01-01 00:00:00 IBM
# 2006-01-01 00:00:00 Oracle
# 2007-01-01 00:00:00 Intel
# 2008-01-01 00:00:00 Yahoo
# 2009-01-01 00:00:00 Alphabet
CodePudding user response:
use a non capturing group ?.* instead of (.*)
df = pd.DataFrame({"A": ["2021-01-01 05:00:00Acme Industries",
"2021-01-01 06:00:00Acme LLC"]})
df.A.str.extract("(\d{4}-\d{2}-\d{2}\s\d{2}:\d{2}:\d{2})?.*")