I've been working with a CSV file. I created a dataframe based on the file:
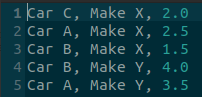
and added index names. and printed the dataframe (with added index names):
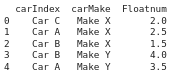
#Here is the code before failed computations.
import pandas as pd
import csv
colName = ['carIndex', 'carMake', 'Floatnum']
data2 = pd.read_csv('cars.csv', names=colName)
print(data2)
I have been trying to extract data to reach my goals although I have had some difficulty. My goals are as follows:
extract data and write alphabetical Dictionary with "carIndex" as key and a value of 0 - 2 (associated with Car A - C)
extract data and write alphabetical Dictionary with "carMake" as key and a value of 0 - 1 (Associated With Make X & Y)
Create (three) key-value pairs for the make "X" & "Y"'s values (associated with carIndex A-C) If a value doesn't exist the index should be None. append all three to a list of lists.
Finally take all three fields (First Dictionary, Second Dictionary, List-of-lists) and add them to a tuple for exportation
Anyone have suggestions for how I can extract the data as I want? Thanks in advance.
In Response to:
Will you please add two things to the question: 1. a text version of your dataframe (preferrably from print(df.to_dict())), and 2. a sample dataframe containing your expected output?
print(data2.to_dict()) (outputs) --> {'carIndex': {0: 'Car C', 1: 'Car A', 2: 'Car B', 3: 'Car B', 4: 'Car A'}, 'carMake': {0: ' Make X', 1: ' Make X', 2: ' Make X', 3: ' Make Y', 4: ' Make Y'}, 'Floatnum': {0: 2.0, 1: 2.5, 2: 1.5, 3: 4.0, 4: 3.5}}
Output Tuple I want: print(my_tup) (outputs) --> ({'Car A': 0, 'Car B': 1, 'Car C': 2}, {'Make X': 0, ' Make Y': 1}, [[2.5, 3.5], [1.5, 4.0], [1.0, None]])
CodePudding user response:
Extract data and write alphabetical Dictionary with "carIndex" as key and a value of 0 - 2 (associated with Car A - C)
sorted = data2.sort_values('carIndex').drop_duplicates(subset='carIndex').reset_index()
carIndexDict = sorted['carIndex'].to_dict()
This will output
{0: 'Car A', 1: 'Car B', 2: 'Car C'}
Extract data and write alphabetical Dictionary with "carMake" as key and a value of 0 - 1 (Associated With Make X & Y)
Use the same strategy:
sorted = data2.sort_values('carMake').drop_duplicates(subset='carMake').reset_index()
carMakeDict = sorted['carMake'].to_dict()
Output:
{0: 'Make X', 1: 'Make Y'}
To make the list:
carIndexes = carIndexDict.values()
carMakes = carMakeDict.values()
full_list = []
for idx in carIndexes:
idx_search = data2.loc[df['carIndex'] == idx]
car_list = []
for make in carMakes:
make_search = idx_search.loc[idx_search['carMake'] == make]
if not make_search.empty:
car_list.append(make_search['Floatnum'].iloc[0])
else:
car_list.append(None)
full_list.append(car_list)
Outputs:
[[2.5, 3.5], [1.5, 4.0], [2.0, None]]
And finally the tuple:
myTuple = (carIndexDict, carMakeDict, full_list)
Outputs:
({0: 'Car A', 1: 'Car B', 2: 'Car C'}, {0: 'Make X', 1: 'Make Y'}, [[2.5, 3.5], [1.5, 4.0], [2.0, None]])