Using:
import pandas as pd
import numpy as np
df = pd.DataFrame(np.random.randint(0,3,(100000,5000)))
df = df.loc[:, (df != 0).any(axis=0)]
to get rid of columns containing only zeros is way too slow for a very large (1000000x2000) dataframe. Any suggestions how to speed this up?
Thanks
CodePudding user response:
Numpy is known to operate substantially faster than Pandas.
So to discover which columns contain only zeroes use:
np.all(np.equal(df.values, 0), axis=0)
But your task is to drop these columns in a DataFrame, as I suppose, keeping source column names.
So the actual drop must be performed on the source Dataframe, using loc and negated result of the above check.
Something like:
df = df.loc[:, ~np.all(np.equal(df.values, 0), axis=0)]
CodePudding user response:
There is a much faster way to implement that using Numba.
Indeed, most of the Numpy implementation will create huge temporary arrays that are slow to fill and read. Moreover, Numpy will iterate over the full dataframe while this is often not needed (at least in your example). The point is that you can very quickly know if you need to keep a column by just iteratively check column values and early stop the computation of the current column if there is any 0 (typically at the beginning). Moreover, there is no need to always copy the entire dataframe (using about 1.9 GiB of memory): when all the columns are kept. Finally, you can perform the computation in parallel.
However, there are performance-critical low-level catches. First, Numba cannot deal with Pandas dataframes, but the conversion to a Numpy array is almost free using df.values (the same thing applies for the creation of a new dataframe). Moreover, regarding the memory layout of the array, it could be better to iterate either over the lines or over the columns in the innermost loop.
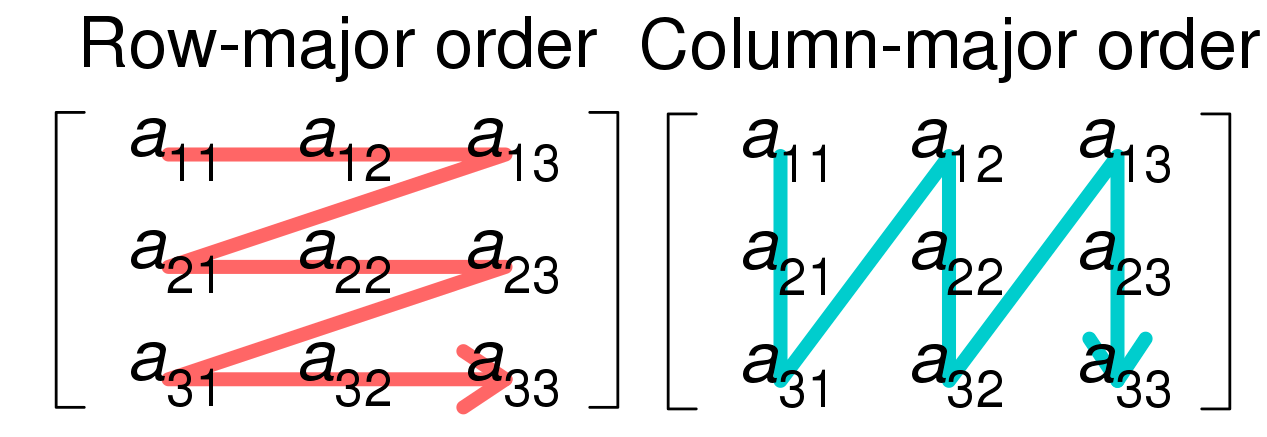
This layout can be fetched by checking the strides of the input dataframe Numpy array.
Note that the example use a row-major dataframe due to the (unusual) Numpy random initialization, but most dataframes tend to be column major.
Here is an optimized implementation:
import numba as nb
@nb.njit('int_[:,:](int_[:,:])', parallel=True)
def filterNullColumns(dfValues):
n, m = dfValues.shape
s0, s1 = dfValues.strides
columnMajor = s0 < s1
toKeep = np.full(m, False, dtype=np.bool_)
# Find the columns to keep
# Only-optimized for column-major dataframes (quite complex otherwise)
for colId in nb.prange(m):
for rowId in range(n):
if dfValues[rowId, colId] != 0:
toKeep[colId] = True
break
# Optimization: no columns are discarded
if np.all(toKeep):
return dfValues
# Create a new dataframe
newColCount = np.sum(toKeep)
res = np.empty((n,newColCount), dtype=dfValues.dtype)
if columnMajor:
newColId = 0
for colId in nb.prange(m):
if toKeep[colId]:
for rowId in range(n):
res[rowId, newColId] = dfValues[rowId, colId]
newColId = 1
else:
for rowId in nb.prange(n):
newColId = 0
for colId in range(m):
res[rowId, newColId] = dfValues[rowId, colId]
newColId = toKeep[colId]
return res
result = pd.DataFrame(filterNullColumns(df.values))
Here are the result on my 6-core machine:
Reference: 1094 ms
Valdi_Bo answer: 1262 ms
This implementation: 0.056 ms (300 ms with discarded columns)
This, the implementation is about 20 000 times faster than the reference implementation on the provided example (no discarded column) and 4.2 times faster on more pathological cases (only one column discarded).
If you want to reach even faster performance, then you can perform the computation in-place (dangerous, especially due to Pandas) or use smaller datatypes (like np.uint8 or np.int16) since the computation is mainly memory-bound.