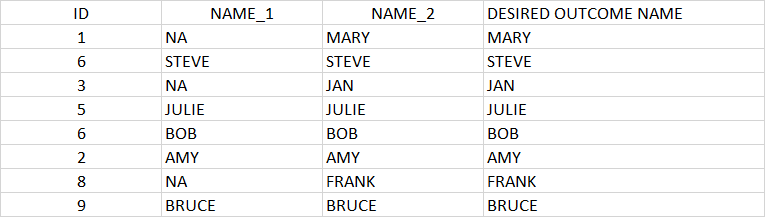
I have a very large file where I have merged two customer databases. The key is the ID. Where the customer name did not match it shows an NA. I need to accomplish a simple if/then statement where if there is "NA" in column NAME_1 the DESIRED OUTCOME NAME is what is in NAME_2, else use what is in NAME_1
I attempted the following code but get errors
df <- df %>% if (df$NAME_1 == "NA") rename(df$NAME_1 == df$NAME_2)
CodePudding user response:
Simply done with
df$NAME_1[is.na(df$NAME_1)] <- df$NAME_2[is.na(df$NAME_1)]
This is just subsetting the values in each of the vectors to elements in positions where it is NA in NAME_1
CodePudding user response:
a solution with dummy data acording to the info you supplied:
df <- data.frame(ID = c(1,6,3,5,6,2,8,9),
NAME_1 = c(NA, "STEVE", NA, "JULIE", "BOB", "AMY", NA, "BRUCE"),
NAME_2 = c("MARY", "STEVE", "JAN", "JULIE", "BOB", "AMY", "FRANK", "BRUCE"))
library(dplyr)
df %>%
dplyr::mutate(NEW_COLUMN = ifelse(is.na(NAME_1), NAME_2, NAME_1))
CodePudding user response:
Using ifelse from base R,
df$'DESIRED OUTCOME NAME' = ifelse(is.na(df$NAME_1), df$NAME_2, df$NAME_1)
CodePudding user response:
In this particular case, the simplest solution would be to use dplyr::coalesce
library(dplyr)
df %>% mutate(`DESIRED OUTCOME NAME` = coalesce(NAME_1, NAME_2))
ID NAME_1 NAME_2 DESIRED OUTCOME NAME
1 1 <NA> MARY MARY
2 6 STEVE STEVE STEVE
3 3 <NA> JAN JAN
4 5 JULIE JULIE JULIE
5 6 BOB BOB BOB
6 2 AMY AMY AMY
7 8 <NA> FRANK FRANK
8 9 BRUCE BRUCE BRUCE