I have a dataframe that looks like this:
| symbol | side | min | max | mean | wav |
|---|---|---|---|---|---|
| 1000038 | buy | 0.931 | 1.0162 | 0.977 | 0.992 |
| 1000038 | sell | 0.932 | 1.0173 | 0.978 | 0.995 |
| 1000039 | buy | 0.881 | 1.00 | 0.99 | 0.995 |
| 1000039 | sell | 0.885 | 1.025 | 0.995 | 1.001 |
What is the most pythonic (efficient) way of generating a new dataframe consisting of the differences between the buys and the sells of each symbol.
For example: symbol 1000038, the difference between the and min sell and min buy is (0.932 - 0.931) = 0.001.
I am seeking a method that avoids looping through the dataframe rows as I believe this would be inefficient. Instead looking for a grouping type of solution.
I have tried something like this:
df1 = stats[['symbol','side']].join(stats[['mean','wav']].diff(-1))
df2 = df1[df1['side']=='sell']
print(df2)
but it does not seem to work as expected.
CodePudding user response:
You could use the pandas MultiIndex. First, set up the data:
import pandas as pd
columns = ('symbol', 'side', 'min', 'max', 'mean', 'wav')
data = [
(1000038, 'buy', 0.931, 1.0162, 0.977, 0.992),
(1000038, 'sell', 0.932, 1.0173, 0.978, 0.995),
(1000039, 'buy', 0.881, 1.00, 0.99, 0.995),
(1000039, 'sell', 0.885, 1.025, 0.995, 1.001),
]
df = pd.DataFrame(data = data, columns = columns)
Then, create the index and compute the difference between two data frames:
df2 = df.set_index(['side', 'symbol'], verify_integrity=True)
df2 = df2.sort_index()
df2.loc[('buy',), :] - df2.loc[('sell',), :]
The result is:
min max mean wav
symbol
1000038 -0.001 -0.0011 -0.001 -0.003
1000039 -0.004 -0.0250 -0.005 -0.006
I'm assuming that each symbol (like 1000038) appears twice. You could use fillna() if you have un-matched buys and sells.
CodePudding user response:
If needed, start with 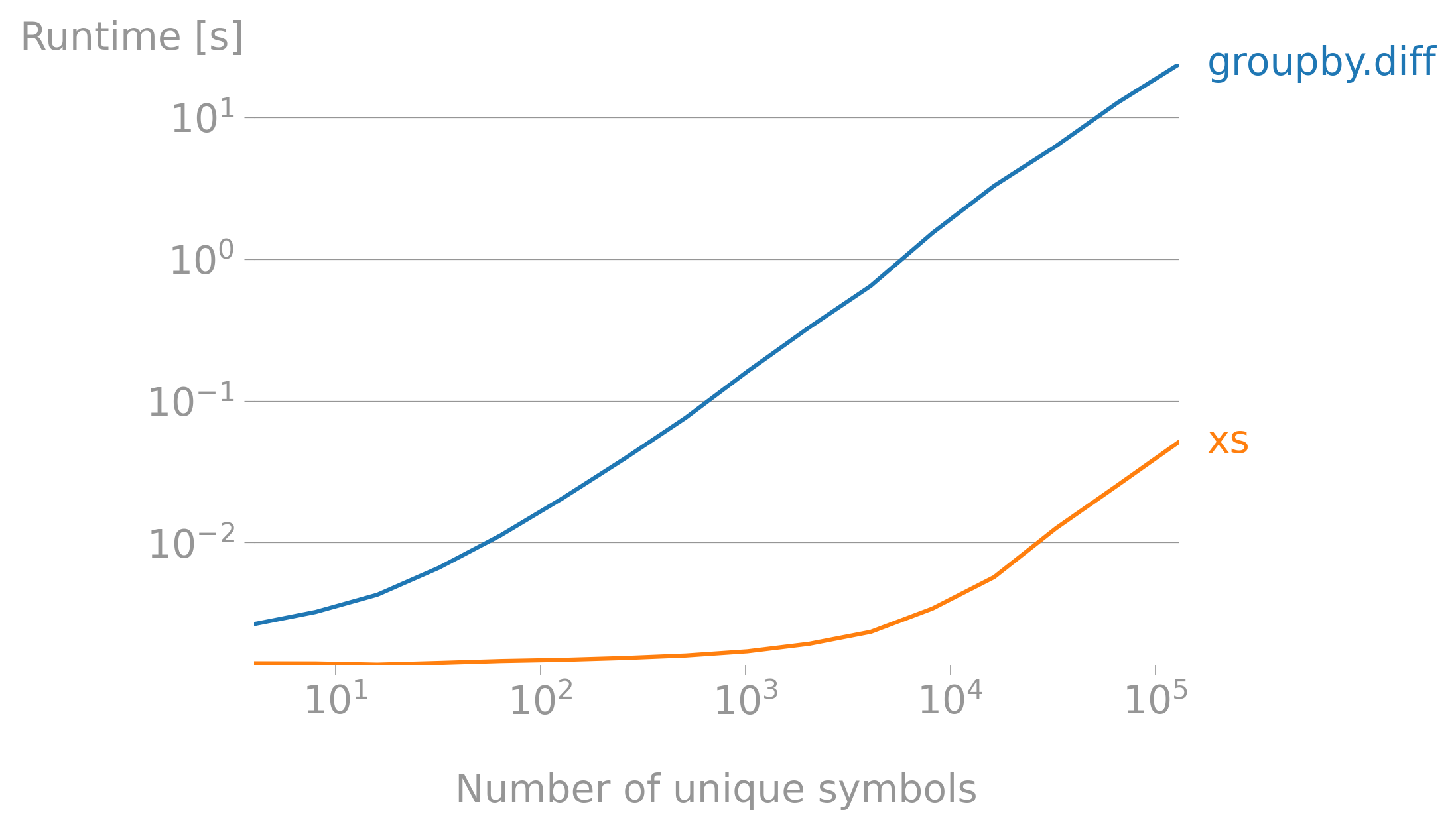
xs
Set the index to ['side', 'symbol'] and use xs to get cross-sections for buy and sell:
df.set_index(['side', 'symbol']).pipe(lambda df: df.xs('sell') - df.xs('buy'))
# min max mean wav
# symbol
# 1000038 0.001 0.0011 0.001 0.003
# 1000039 0.004 0.0250 0.005 0.006
groupby.diff
Set the index to symbol and subtract the groups using groupby.diff:
df.drop(columns='side').set_index('symbol').groupby('symbol').diff().dropna()
# min max mean wav
# symbol
# 1000038 0.001 0.0011 0.001 0.003
# 1000039 0.004 0.0250 0.005 0.006
diff(-1).- If your version throws an error with
groupby('symbol'), use groupby(level=0).