I have a CSV file which looks like
K1
,Value
M1,0
M2,10
M3,3
K2
,Value,Value,Value
M1,4,6,3
M2,7,3,4
M3,10,2,6
K1
,Value,Value
M1,0,4
M2,10,2
M3,3,7
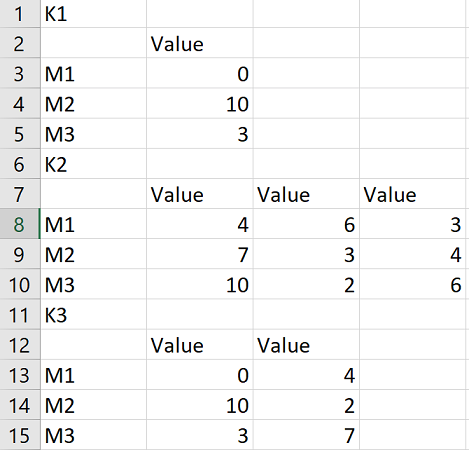
The file is grouped by 5 rows. For example, the name of the first group is K1, followed by a dataframe with fixed 3 rows and 1 columns. The number of rows in groups are fixed but the number of columns is variable. K1 has 1 column, K2 has 3 columns and K3 has two columns. I want to read that to form a dictionary where the key is the name of the group, K1, K2 or K3 and the value is dataframe associated with the group name.
The simple read_csv like df = pd.read_csv('test.batch.csv') fails with the following error
Traceback (most recent call last):
File "test.py", line 8, in <module>
df = pd.read_csv('test.batch.csv')
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 610, in read_csv
return _read(filepath_or_buffer, kwds)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 468, in _read
return parser.read(nrows)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 1057, in read
index, columns, col_dict = self._engine.read(nrows)
File "/home/mahmood/.local/lib/python3.8/site-packages/pandas/io/parsers.py", line 2061, in read
data = self._reader.read(nrows)
File "pandas/_libs/parsers.pyx", line 756, in pandas._libs.parsers.TextReader.read
File "pandas/_libs/parsers.pyx", line 771, in pandas._libs.parsers.TextReader._read_low_memory
File "pandas/_libs/parsers.pyx", line 827, in pandas._libs.parsers.TextReader._read_rows
File "pandas/_libs/parsers.pyx", line 814, in pandas._libs.parsers.TextReader._tokenize_rows
File "pandas/_libs/parsers.pyx", line 1951, in pandas._libs.parsers.raise_parser_error
pandas.errors.ParserError: Error tokenizing data. C error: Expected 2 fields in line 7, saw 4
I know the file is not properly formatted for read_csv(), so I would like to know if there is any other read function to use like that. Any idea about that?
CodePudding user response:
My idea is to start from an empty intermediate dictionary.
Then read a single line from the input file (the key) and following 4 lines as the value and add them to the dictionary.
The final step is to "map" this dictionary, using a dictionary comprehension, changing each (string) value into a DataFrame.
To do it, you can use read_csv, passing the value of the current key as the source content.
So the source code can be e.g.:
wrk = {}
with open('Input.csv') as fp:
while True:
cnt1 = 1
line = fp.readline()
if not line:
break
key = line.strip()
txt = [ fp.readline().strip() for i in range(4) ]
txt = '\n'.join(txt)
wrk[key] = txt
result = { k: pd.read_csv(io.StringIO(v), index_col=[0]) for k, v in wrk.items() }
Note however a side effect, resulting from how read_csv works:
If column names are not unique then Pandas adds a dot and consecutive numbers to such "repeating" columns.
So e.g. the content of K2 key in result is:
Value Value.1 Value.2
M1 4 6 3
M2 7 3 4
M3 10 2 6
Or maybe actual column names in each input "section" are not the same?
To sum up, at least this code allows you to circumvent the limitation concerning same number of columns while reading a single DataFrame.