i have a data frame that looks like this:
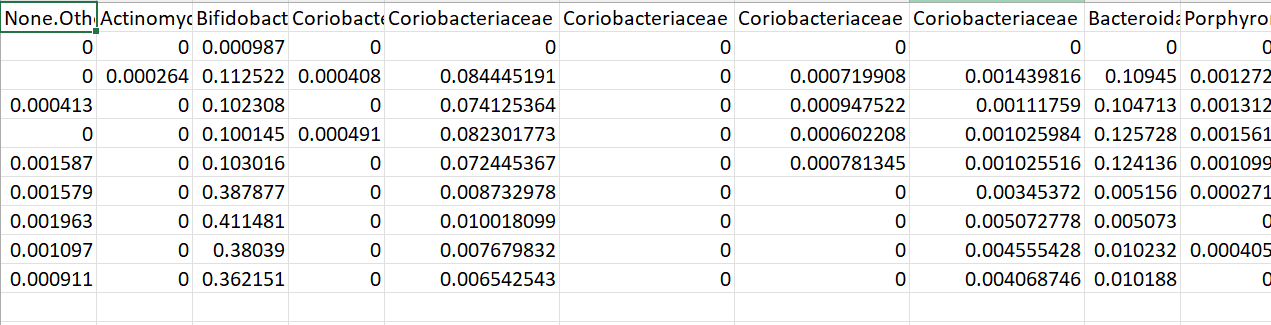
there are in total 109 columns. when i import the data using the read_csv it adds ".1",".2" to duplicate names . is there any way to go around it ?
i have tried this :
df = pd.read_csv(r'C:\Users\agns1\Downloads\treatment1.csv',encoding = "ISO-8859-1",
sep='|', header=None)
df = df.rename(columns=df.iloc[0], copy=False).iloc[1:].reset_index(drop=True)
but it changed the data frame and wasnt helpful. this is what it did to my data python:
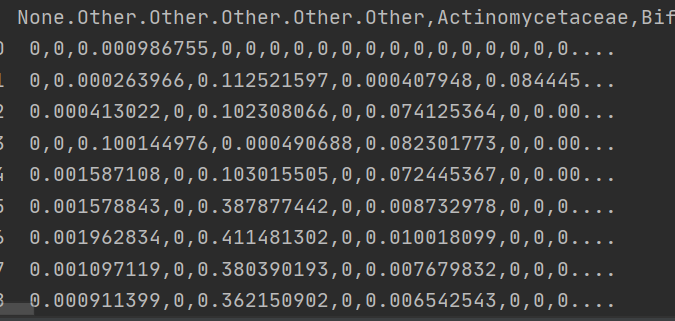
excel:

CodePudding user response:
Remove header=None, because it is used for avoid convert first row of file to df.columns and then remove . with digits from columns names:
df = pd.read_csv(r'C:\Users\agns1\Downloads\treatment1.csv',encoding="ISO-8859-1", sep=',')
df.columns = df.columns.str.replace('\.\d $','')