I'm trying to scrape "1,335,000" from the screenshot below (the number is at the bottom of the screenshot). I wrote the following code in R.
t2<-read_html("https://fortune.com/company/amazon-com/fortune500/")
employee_number <- t2 %>%
rvest::html_nodes('body') %>%
xml2::xml_find_all("//*[contains(@class, 'info__value--2AHH7')]") %>%
rvest::html_text()
However, when I call "employee_number", it gives me "character(0)". Can anyone help me figure out why?
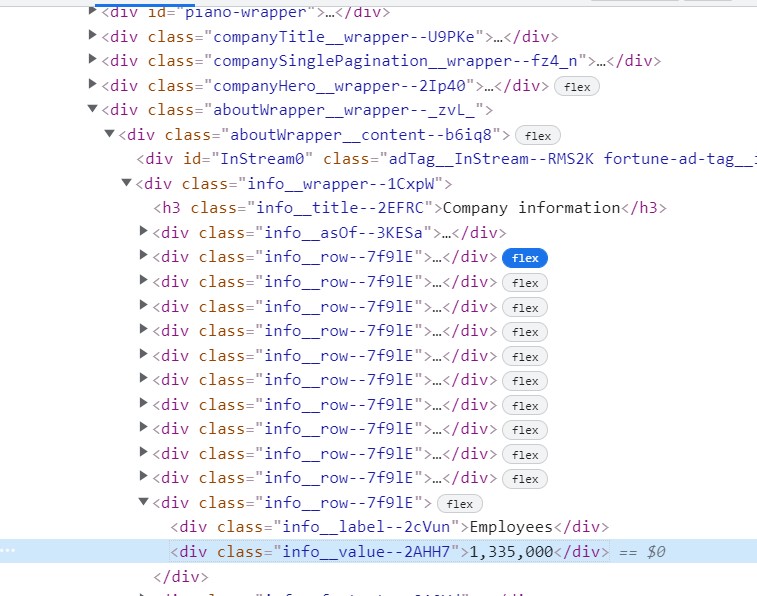
CodePudding user response:
As Dave2e pointed the page uses javascript, thus can't make use of rvest.
url = "https://fortune.com/company/amazon-com/fortune500/"
#launch browser
library(RSelenium)
driver = rsDriver(browser = c("firefox"))
remDr <- driver[["client"]]
remDr$navigate(url)
remDr$getPageSource()[[1]] %>%
read_html() %>% html_nodes(xpath = '//*[@id="content"]/div[5]/div[1]/div[1]/div[12]/div[2]') %>%
html_text()
[1] "1,335,000"
CodePudding user response:
Data is loaded dynamically from a script tag. No need for expense of a browser. You could either extract the entire JavaScript object within the script, pass to jsonlite to handle as JSON, then extract what you want, or, if just after the employee count, regex that out from the response text.
library(rvest)
library(stringr)
library(magrittr)
library(jsonlite)
page <- read_html('https://fortune.com/company/amazon-com/fortune500/')
data <- page %>% html_element('#preload') %>% html_text() %>%
stringr::str_match(. , "PRELOADED_STATE__ = (.*);") %>% .[, 2] %>% jsonlite::parse_json()
print(data$components$page$`/company/amazon-com/fortune500/`[[6]]$children[[4]]$children[[3]]$config$employees)
#shorter version
print(page %>%html_text() %>% stringr::str_match('"employees":"(\\d )?"') %>% .[,2] %>% as.integer() %>% format(big.mark=","))