I have a dataset with quest and several topics. After applying the "describe" function (from the psych package), how can I list all results in a convenient way ?
The results I've got:
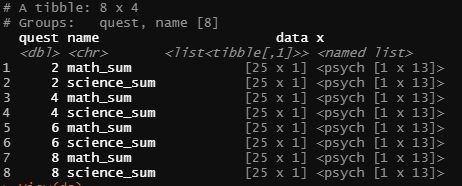
The desired output is something like that:

ds <- data.frame(quest = c(2,4,6,8), math_sum = rnorm(100,10,1), science_sum = rnorm(100,8,1))
ds %>%
select(quest, ends_with("sum")) %>%
pivot_longer(-quest) %>%
nest_by(quest, name) %>%
mutate(x=list(map(data, ~psych::describe(.)))) %>%
unnest(-data)
CodePudding user response:
You could use unnest_wider():
library(tidyverse)
ds %>%
select(quest, ends_with("sum")) %>%
pivot_longer(-quest) %>%
nest_by(quest, name) %>%
mutate(x=list(map(data, ~psych::describe(.)))) %>%
unnest_wider(x) %>%
unnest_wider(value)
This returns
# A tibble: 8 x 16
quest name data vars n mean sd median trimmed mad min max
<dbl> <chr> <list<tib> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2 math_s~ [25 x 1] 1 25 10.3 1.22 10.1 10.3 0.963 7.96 12.9
2 2 scienc~ [25 x 1] 1 25 7.55 1.00 7.48 7.56 1.19 5.49 9.22
3 4 math_s~ [25 x 1] 1 25 9.59 0.998 9.50 9.58 0.858 7.31 11.6
4 4 scienc~ [25 x 1] 1 25 8.07 1.28 8.24 8.01 1.70 6.13 10.6
5 6 math_s~ [25 x 1] 1 25 9.85 0.932 9.79 9.79 0.929 8.50 11.8
6 6 scienc~ [25 x 1] 1 25 7.80 0.907 7.81 7.79 0.959 6.03 9.69
7 8 math_s~ [25 x 1] 1 25 10.2 1.19 10.4 10.2 1.06 8.09 13.1
8 8 scienc~ [25 x 1] 1 25 8.01 0.923 7.88 7.99 0.908 6.23 9.87
# ... with 4 more variables: range <dbl>, skew <dbl>, kurtosis <dbl>, se <dbl>