I am using python socket to write a persistent http server. I think that the style.css file should be transfer through the same port number, but it seems like I didn't get the result. Packets no.48 and 49 show that the style.css is transfers through different port compare to packet 37.
I think there might be something wrong in the header of res_for_good.
import socket
from datetime import datetime
import threading
res_for_good = '''HTTP/1.1 200 OK\r
Date: Sun, 18 Oct 2012 10:36:20 GMT\r
Accept-Ranges: bytes\r
Content-Type: text/html; charset=iso-8859-1\r
Connection: keep-alive\r
Keep-Alive: timeout=3 max=5\r
Content-Length: 112\r
\r
<head>
<link rel="stylesheet" href="./style.css" type="text/css">
</head>
<html>
<body>good HaHa</body>
</html>
'''
res_for_notfound='''HTTP/1.1 404 Not Found\r
Date: Sun, 18 Oct 2012 10:36:20 GMT\r
Accept-Ranges: bytes\r
Content-Type: text/html; charset=iso-8859-1\r
Connection: keep-alive\r
Keep-Alive: timeout=3 max=5\r
Content-Length: 116\r
\r
<head>
<link rel="stylesheet" href="./style.css" type="text/css">
</head>
<html>
<body>404 Not Found</body>
</html>
'''
res_for_style='''HTTP/1.1 200 OK\r
Date: Sun, 18 Oct 2012 10:36:20 GMT\r
Accept-Ranges: bytes\r
Content-Type: text/css; charset=iso-8859-1\r
Keep-Alive: timeout=3 max=5\r
Connection: keep-alive\r
Content-Length: 46\r
\r
body{
color: red;
font-size: 100px;
}
'''
def serveClient(clientsocket, address):
start = datetime.now()
objcount=0
# we need a loop to continuously receive messages from the client
while True:
objcount =1
# then receive at most 1024 bytes message and store these bytes in a variable named 'data'
# you can set the buffer size to any value you like
data = clientsocket.recv(1024)
data_utf8=data.decode('utf-8').split('\r\n')
#data_json = json.loads(data_utf8)
print(address)
print(data)
# if the received data is not empty, then we send something back by using send() function
if '/good.html' in data_utf8[0]:
clientsocket.sendall(res_for_good.encode())
if '/style.css' in data_utf8[0]:
print("transfer css")
#res="Content-Type: text/css\n\n" css_file.read()
res=res_for_style
clientsocket.sendall(res_for_style.encode())
if '/redirect.html' in data_utf8[0]:
clientsocket.sendall(res_for_redirect.encode())
elif data:
clientsocket.sendall(res_for_notfound.encode())
if data == b'':
objcount-=1
print("object count: " str(objcount))
now = datetime.now()
# we need some condition to terminate the socket
# lets see if the client sends some termination message to the server
# if so, then the server close the socket
if objcount == max_rec_Object or (now-start).total_seconds()>waiting_time:
print(start)
print(now)
print('close socket')
clientsocket.close()
break
while True:
# accept a new client and get it's informati
# print(socket.gethostbyaddr(s.getpeername))
(clientsocket, address) = s.accept()
# create a new thread to serve this new client
# after the thread is created, it will start to execute 'target' function with arguments 'args'
threading.Thread(target = serveClient, args = (clientsocket, address)).start()
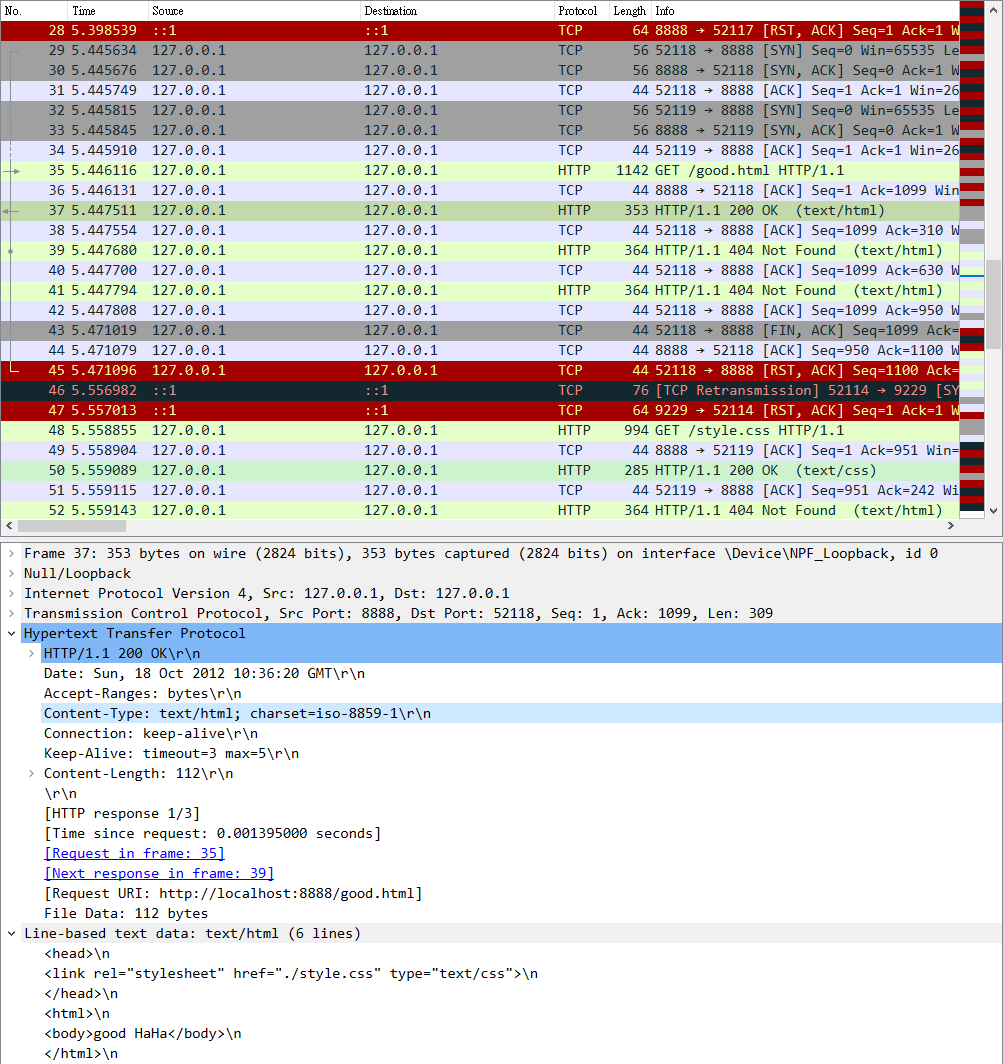
CodePudding user response:
I think that the style.css file should be transfer through the same port number
First, there is no requirement in HTTP/1.1 which says so. Then, there are bugs in your code.
First the bugs: as seen from the packet capture your server responds to a single request for /good.html with 3 HTTP responses: one is the expected 200, the two other are unexpected 404. The first wrong 404 is due to this code:
if '/good.html' in data_utf8[0]:
clientsocket.sendall(res_for_good.encode())
...
if '/redirect.html' in data_utf8[0]:
clientsocket.sendall(res_for_redirect.encode())
elif data:
clientsocket.sendall(res_for_notfound.encode())
Since it does not stop after handling /good.html it will eventually end up in the last shown line and send res_for_notfound.
The second wrong 404 is due to this code:
while True: ... data = clientsocket.recv(1024) ... elif data: clientsocket.sendall(res_for_notfound.encode())
Here is blindly assumes that the request will not exceed 1024 and that it will be read within a single recv. Both assumptions are wrong. From the packet capture can be seen that the request is actually 1098 bytes (look at the ACK=1099). And even if it would be less than 1024 there would be no guarantee that it will be read within a single recv, that's not how TCP works.
Because of the two extraneous 404 responses the client correctly assumes that the server is incapable of sending correct responses and thus closes the connection to get back to a sane state.
That said, even with a correct response there would be no guarantee that the second request comes in through the same TCP connection. Explicitly or implicitly announcing support for HTTP keep alive just means that client and server support the reuse of a TCP connection for another HTTP request. It does not mean that a specific existing TCP connection must be used for the next request nor that any existing TCP connection must be used at all instead of creating a new one.
From the packet capture can be seen that the browser initially opens two TCP connections to the server. This is not uncommon, since typically a site includes many resources which should be retrieved as fast as possible. Only HTTP/1.1 can only sequentially and not in parallel retrieve resources over a single TCP connection. So it is a good idea to have another spare TCP connection ready. This other already existing connection then gets used in your case for the new resource.