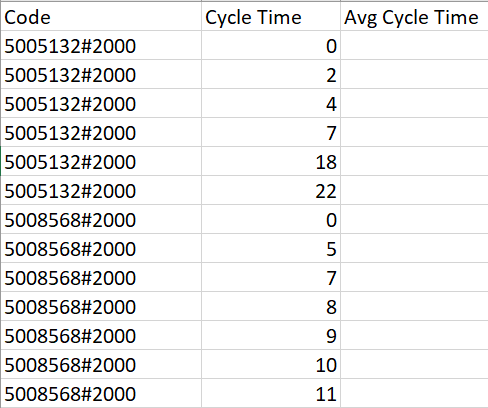
I have a data like this. There are six entries for the code 5005132#2000, in which '0' is the minimum and maximum is '22' and for the code 5008568#2000, there are 7 entries, in which '0' is the minimum and '11' is the maximum. I have to remove these minimum and maximum values related to the particular codes and compute the 'Average' for the particular code.
The avg of 5005132#2000 should be 7.75 and The avg of 5008568#2000 should be 7.8
CodePudding user response:
One solution is to use data.table. The data.table is like a data.frame but with added fuctionality. You will first need to load the data.table package and convert your data.frame (df) to a data.table
library(data.table)
setDT(df)
From there, filter out the values at the extremes for each group using by, then get the mean of the remaining values.
# Solution:
df[,
# ID rows where value is min/max
.(Cycle.Time, "drop" = Cycle.Time %in% range(Cycle.Time)), by=Code][
# Filter to those where value is not mon/max and get mean per Code
drop==FALSE, mean(Cycle.Time), by=Code]
An alternative is to use dplyr
df %>%
group_by(Code) %>%
filter(!Cycle.Time %in% range(Cycle.Time)) %>%
summarize(mean(Cycle.Time))
And to store that in a data.frame:
df %>%
group_by(Code) %>%
filter(!Cycle.Time %in% range(Cycle.Time)) %>%
summarize(mean(Cycle.Time)) %>%
data.frame -> averages