Here is a sample of the data I'm working with
| county | urban_continuum | p.shannon | p.simpson |
|---|---|---|---|
| Brunswick | B_Town | 3.804079 | 0.9744810 |
| Accomack | A_Rural | 3.830896 | 0.9771901 |
| Buena Vista | B_Town | 3.970617 | 0.9802289 |
| Amherst | D_City | 4.007048 | 0.9813272 |
| Buckingham | C_Suburb | 4.055685 | 0.9796187 |
| Campbell | D_City | 4.161142 | 0.9837963 |
| Cumberland | A_Rural | 4.229130 | 0.9850256 |
| Danville | C_Suburb | 4.631135 | 0.9888504 |
Note: "p.simpson" and "p.shannon" refer to simpson diversity and shannon diversity
I'm trying to get the mean and the standard deviation for each category (e.g. the mean for "B_Town" is 3.97235).
I first used aggregate. Here's what I have for the mean (the code for standard deviation is the same but FUN="sd"):
urbancon_div.mean=aggregate(p.simpson~urban_continuum p.shannon, data=plant.co, FUN="mean")
Here's what R gives me:
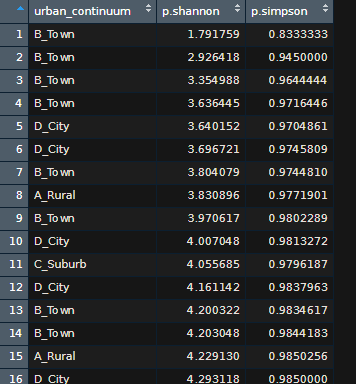
Notice that even when "county" is not in the code, it still gives me means for individual counties. I'm trying to find the mean of each diversity metric for each category across all counties. How do I get the mean and sd for each category across all counties not by individual counties?
CodePudding user response:
You may try using dplyr
library(dplyr)
plant.co <- read.table(text = "county urban_continuum p.shannon p.simpson
Brunswick B_Town 3.804079 0.9744810
Accomack A_Rural 3.830896 0.9771901
'Buena Vista' B_Town 3.970617 0.9802289
Amherst D_City 4.007048 0.9813272
Buckingham C_Suburb 4.055685 0.9796187
Campbell D_City 4.161142 0.9837963
Cumberland A_Rural 4.229130 0.9850256
Danville C_Suburb 4.631135 0.9888504", header = T)
plant.co %>%
group_by(urban_continuum) %>%
summarize(p.shannon.mean = mean(p.shannon),
p.shannon.sd = sd(p.shannon),
p.simpson.mean = mean(p.simpson),
p.simpson.sd = sd(p.simpson))
urban_continuum p.shannon.mean p.shannon.sd p.simpson.mean p.simpson.sd
<chr> <dbl> <dbl> <dbl> <dbl>
1 A_Rural 4.03 0.282 0.981 0.00554
2 B_Town 3.89 0.118 0.977 0.00406
3 C_Suburb 4.34 0.407 0.984 0.00653
4 D_City 4.08 0.109 0.983 0.00175
CodePudding user response:
If you are using aggregate:
aggregate(cbind(p.simpson, p.shannon)~urban_continuum, df, \(x)c(mean = mean(x), sd = sd(x)))
urban_continuum p.simpson.mean p.simpson.sd p.shannon.mean p.shannon.sd
1 A_Rural 0.981107850 0.005540535 4.0300130 0.2815940
2 B_Town 0.977354950 0.004064379 3.8873480 0.1177601
3 C_Suburb 0.984234550 0.006527798 4.3434100 0.4069046
4 D_City 0.982561750 0.001745917 4.0840950 0.1089609
or simply:
aggregate(.~urban_continuum, df[-1], \(x)c(mean = mean(x), sd = sd(x)))