Suppose I have a pivot like this:
import pandas as pd
d = {'Col_A': [1,2,3,3,3,4,9,9,10,11],
'Col_B': ['A','K','E','E','H','A','J','A','L','A'],
'Value1':[648,654,234,873,248,45,67,94,180,120],
'Value2':[180,120,35,654,789,34,567,21,235,83],
'Value3':[567,21,235,83,248,45,67,94,180,120]
}
df = pd.DataFrame(data=d)
df_pvt = pd.pivot_table(df,values=['Value1'], index='Col_A', columns='Col_B', aggfunc=np.sum).fillna(0)
df_pvt
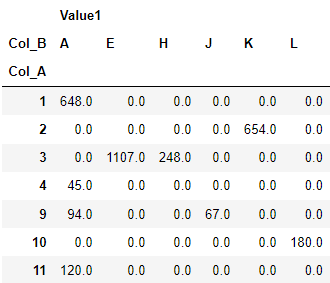
I want to add a calculated field at the right side of the pivot using "Value2/Value3". This calculated field should also display with Col_B categories. One way to do it is to add Value2, and Value3 in the pivot and do the division afterwards. Then, I could just drop those Value 2 and Value 3 sections in the pivot. However, I'm wondering if there's any easier way to achieve this. I've tried the following, but didn't work:
pd.pivot_table(df,values=['Value1','Value2'/'Value3'], index='Col_A', columns=['Col_B','val2/val3'], aggfunc=np.sum).fillna(0)
CodePudding user response:
Apply these transformations before the pivot:
df = df.groupby(['Col_A', 'Col_B']).sum()
df = df.eval('V23 = Value2 / Value3')[['Value1', 'V23']]
Then apply the pivot and clean-up:
df.reset_index().pivot(index='Col_A', columns='Col_B').fillna(0)
UPDATE: In fact, you can replace the last line with just:
df.unstack(fill_value=0)
CodePudding user response:
IIUC, use assign after:
out = df.pivot_table('Value1', 'Col_A', 'Col_B', aggfunc=np.sum).fillna(0) \
.assign(Value4=df.groupby('Col_A')
.apply(lambda x: sum(x['Value2']) / sum(x['Value3'])))
print(out)
# Output:
Col_B A E H J K L Value4
Col_A
1 648.0 0.0 0.0 0.0 0.0 0.0 0.317460
2 0.0 0.0 0.0 0.0 654.0 0.0 5.714286
3 0.0 1107.0 248.0 0.0 0.0 0.0 2.611307
4 45.0 0.0 0.0 0.0 0.0 0.0 0.755556
9 94.0 0.0 0.0 67.0 0.0 0.0 3.652174
10 0.0 0.0 0.0 0.0 0.0 180.0 1.305556
11 120.0 0.0 0.0 0.0 0.0 0.0 0.691667
CodePudding user response:
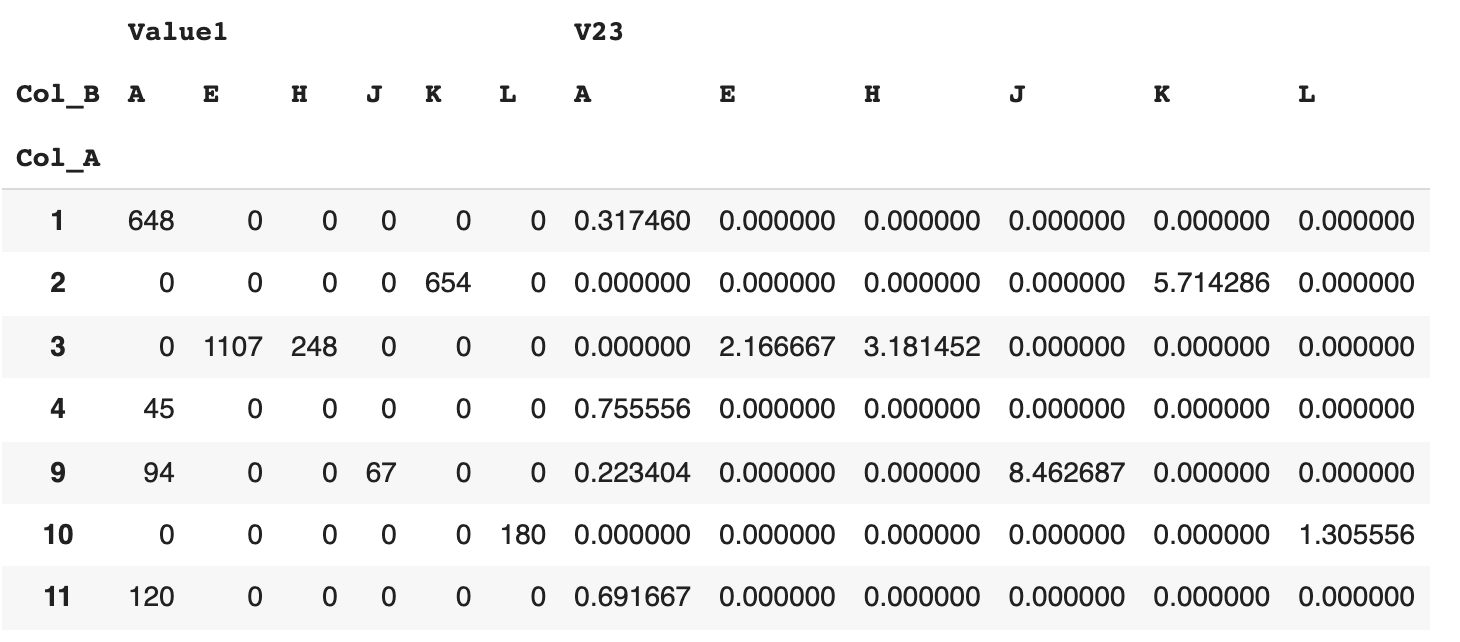
Is this what you're looking for?
out = (df.groupby(['Col_A', 'Col_B']).sum()
.assign(**{'Value2/Value3' : lambda x: x['Value2']/x['Value3']})
.loc[:,['Value1', 'Value2/Value3']]
.unstack(level=1, fill_value=0))
Output:
Value1 Value2/Value3
Col_B A E H J K L A E H J K L
Col_A
1 648 0 0 0 0 0 0.317460 0.000000 0.000000 0.000000 0.000000 0.000000
2 0 0 0 0 654 0 0.000000 0.000000 0.000000 0.000000 5.714286 0.000000
3 0 1107 248 0 0 0 0.000000 2.166667 3.181452 0.000000 0.000000 0.000000
4 45 0 0 0 0 0 0.755556 0.000000 0.000000 0.000000 0.000000 0.000000
9 94 0 0 67 0 0 0.223404 0.000000 0.000000 8.462687 0.000000 0.000000
10 0 0 0 0 0 180 0.000000 0.000000 0.000000 0.000000 0.000000 1.305556
11 120 0 0 0 0 0 0.691667 0.000000 0.000000 0.000000 0.000000 0.000000