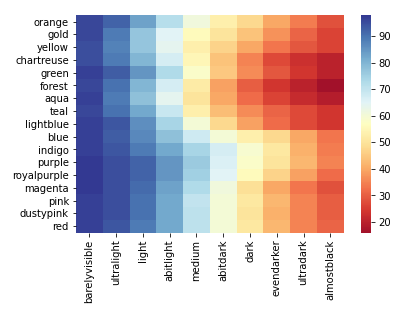
I have a Pandas DataFrame, luminance_df, that looks like this:
| barelyvisible | ultralight | light | abitlight | medium | abitdark | dark | evendarker | ultradark | almostblack | |
|---|---|---|---|---|---|---|---|---|---|---|
| orange | 96 | 92 | 83 | 72 | 61 | 53 | 48 | 40 | 34 | 28 |
| gold | 96 | 89 | 77 | 65 | 56 | 50 | 44 | 37 | 31 | 26 |
| yellow | 95 | 88 | 77 | 64 | 53 | 47 | 40 | 33 | 29 | 26 |
| chartreuse | 95 | 89 | 80 | 67 | 55 | 44 | 35 | 27 | 23 | 20 |
| green | 97 | 93 | 85 | 73 | 58 | 45 | 36 | 29 | 24 | 20 |
| forest | 96 | 90 | 80 | 67 | 52 | 39 | 30 | 24 | 20 | 16 |
| aqua | 97 | 89 | 78 | 64 | 50 | 40 | 32 | 26 | 22 | 19 |
| teal | 96 | 90 | 82 | 69 | 53 | 43 | 36 | 31 | 27 | 24 |
| lightblue | 97 | 94 | 86 | 74 | 60 | 48 | 39 | 32 | 27 | 24 |
| blue | 97 | 93 | 87 | 78 | 68 | 60 | 53 | 48 | 40 | 33 |
| indigo | 97 | 94 | 89 | 82 | 74 | 67 | 59 | 51 | 41 | 34 |
| purple | 98 | 95 | 92 | 85 | 76 | 66 | 58 | 50 | 42 | 35 |
| royalpurple | 98 | 95 | 92 | 85 | 75 | 65 | 56 | 47 | 39 | 32 |
| magenta | 98 | 95 | 91 | 83 | 73 | 61 | 49 | 40 | 33 | 28 |
| pink | 97 | 95 | 90 | 82 | 70 | 60 | 51 | 42 | 35 | 30 |
| dustypink | 97 | 95 | 90 | 82 | 71 | 60 | 50 | 41 | 35 | 30 |
| red | 97 | 94 | 89 | 82 | 71 | 60 | 51 | 42 | 35 | 31 |
So far, I'm building a single multi-chart HTML file like this:
with open(os.path.join(cwd, 'testout.html'), 'w') as outfile:
outfile.write("<p> </p><hr/><p> </p>".join(['<h1>Colors</h1>' hex_styler.to_html(), '<h1>Hue</h1>' hue_styler.to_html(), '<h1>Saturation</h1>' saturation_styler.to_html(
), '<h1>Luminance</h1>' luminance_styler.to_html(), '<h1>Perceived Brightness</h1>' perceived_brightness_pivot_styler.to_html(), '<h1>Base Data</h1>' basic_df.to_html()]))
I'd like to display an elevation/contour style map of the Luminance right after luminance_styler.to_html(), a lot like this one that I produced in Excel:
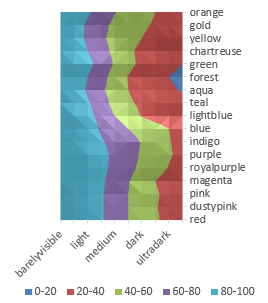
I'd like the colors to stay sorted "top to bottom" as values on a y-axis and the darknesses to stay sorted "left to right" as values on an x-axis, just like in the example above.
Question
I'm not a data scientist, nor do I use Python terribly regularly. I'm proud of myself for having made luminance_df in the first place, but I am not, for the life of me, figuring out how to make Python simply ... treat numeric cell values in a DataFrame whose labels in both directions are strings ... as a z-axis and make a contour-chart of it.
Everything I Google leads to really complicated data science nuanced questions.
Could someone get me on the right track by giving me the basic "hello world" code to get at least as far with luminance_df's data in Python as I got with the "insert chart" button in Excel?
If you can get me so I've got a img = BytesIO() that's image_base64 = base64.b64encode(img.read()).decode("utf-8")-able, I can f'<img src="data:image/png;base64, {image_base64}" />' it myself into the string concatenation that makes testout.html.
I'm on Windows and have myself set up to be able to pip install.
Notes
To be fair, I find these contour charts much more attractive and much easier to read than the one Excel made, but I'm fine with something sort of "brutish"-looking like the Excel version, as long as it makes "rising" & "falling" obvious and as long as it uses a ROYIGBV rainbow to indicate "less" vs. "more" (pet peeve of mine about the default Excel colors -- yes, I know, it's probably an accessibility thing):
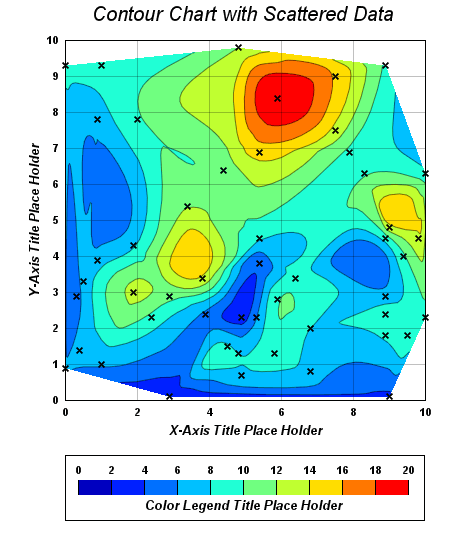
While I'd like my chart's colors to follow a "rainbow" of sorts (because personally I find them easy to read), any "rainbow shading" on the chart should completely ignore the fact that the labels of the y-axis happen to describe colors. No correlation whatsoever. I'm simply plotting number facts between 16 and 98; colors of the chart should just indicate the change in "elevation" between those two extremes.
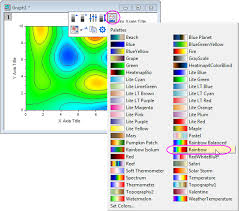
Effort so far
The only other "simple" question I've found so far that seems similar is 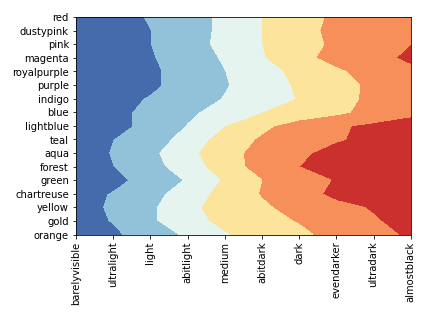
Or a heatmap:
import seaborn as sns
sns.heatmap(df, cmap='RdYlBu')
Output: