I have a CSV file that contains data of magnitude in rising of the tide from different parts of the world and I wrote a code that filters the data read from that CSV file and the code goes like this:
import pandas as pd
import numpy as np
df1=pd.read_csv("Tide Prediction.csv")
df1.columns = df1.iloc[0] #To replace the header with the first row
df1 = df1[1:]
df2=df1.rename(columns={df1.columns[3]: "location"})
dict = {'UTC': 'time',
'degrees_east': 'longitude',
'degress_west': 'latitude'}
df2['degrees_north'] = df2['degrees_north'].astype(float, errors = 'raise')
df2['degrees_east'] = df2['degrees_east'].astype(float, errors = 'raise')
c=np.where(degrees_north>8.06694 & degrees_north < 37.10028, [True]*6885393, [False]*6885393)
But this is giving me an error
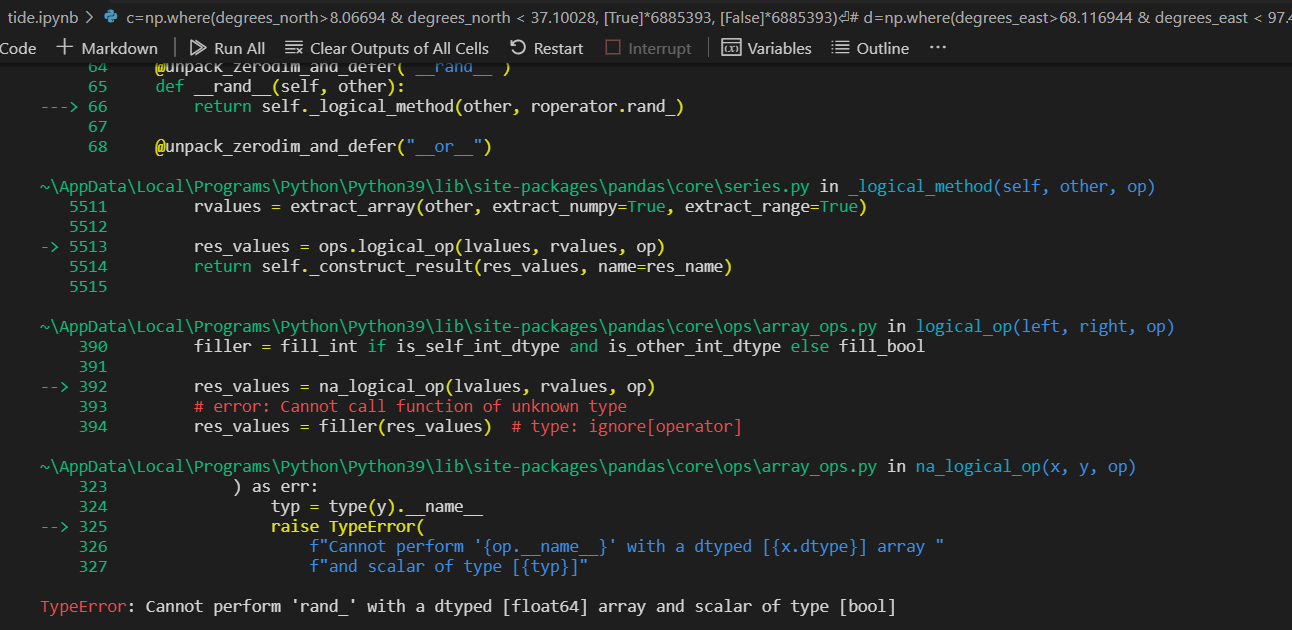
CodePudding user response:
You can use between:
Suppose the following dataframe
df = pd.DataFrame({'degrees_north': [8, 9, 37, 38]})
print(df)
# Output:
degrees_north
0 8
1 9
2 37
3 38
>>> df['degrees_north'].between(8.06694, 37.10028, inclusive='neither')
0 False
1 True
2 True
3 False
Name: degrees_north, dtype: bool
CodePudding user response:
Here np.where is not necessary, because same output if compare only, only need add () for conditions:
c=(degrees_north>8.06694) & (degrees_north < 37.10028)
c=np.where((degrees_north>8.06694) & (degrees_north < 37.10028), True, False)