this is not the most butiful code. And it's too slow when doing what I want it to, so I was hoping someone could tell me a faster way of doing this.
I have a file (of about 800K lines) looking something like the example below, I want to flatten the file so that one userident has all the answers after it (in the example, I would like to have 3 long lines with the info) There is 8 questions pr. user, so this takes way too long to do this way.
userident, qustion, answer, time, answer j/n, amount, text, flag
1,FMTA DYN 01 - PERSON,13:00,'j',14,'some info',0
1,FMTA DYN 02 - PERSON,13:00,'j',14,'some info',0
1,FMTA DYN 03 - PERSON,13:00,'j',14,'some info',0
2,FMTA DYN 01 - PERSON,13:00,'j',14,'some info',0
2,FMTA DYN 02 - PERSON,13:00,'j',14,'some info',0
2,FMTA DYN 03 - PERSON,13:00,'j',14,'some info',0
3,FMTA DYN 01 - PERSON,13:00,'j',14,'some info',0
3,FMTA DYN 02 - PERSON,13:00,'j',14,'some info',0
3,FMTA DYN 03 - PERSON,13:00,'j',14,'some info',0
# This is the question
FORMAL_INFO = ['FMTA DYN 01 - PERSON',
'FMTA DYN 02 - PERSON','FMTA DYN 03 - PERSON','FMTA DYN 04 - PERSON','FMTA DYN 05 - PERSON','FMTA DYN 06 - PERSON','FORMÅL OG TILSIKTA ART KONTANT','FORMÅL OG TILSIKTA ART UTLAND INNB','FORMÅL OG TILSIKTA ART UTLAND UTBET']
column_names = ["userident", "Spørsmål1", "Svar 1", "tid1", "svar j/n1","SVAR_BELOP1","SVAR_TEKST1","selvbetjent flag1",
"Spørsmål2", "Svar 2", "tid2", "svar j/n2","SVAR_BELOP2","SVAR_TEKST2","selvbetjent flag2",
"Spørsmål3", "Svar 3", "tid3", "svar j/n3","SVAR_BELOP3","SVAR_TEKST3","selvbetjent flag3",
"Spørsmål4", "Svar 4", "tid4", "svar j/n4","SVAR_BELOP4","SVAR_TEKST4","selvbetjent flag4",
"Spørsmål5", "Svar 5", "tid5", "svar j/n5","SVAR_BELOP5","SVAR_TEKST5","selvbetjent flag5",
"Spørsmål6", "Svar 6", "tid6", "svar j/n6","SVAR_BELOP6","SVAR_TEKST6","selvbetjent flag6",
"Spørsmål7", "Svar 7", "tid7", "svar j/n7","SVAR_BELOP7","SVAR_TEKST7","selvbetjent flag7",
"Spørsmål8", "Svar 8", "tid8", "svar j/n8","SVAR_BELOP8","SVAR_TEKST8","selvbetjent flag8",
"Spørsmål9", "Svar 9", "tid9", "svar j/n9","SVAR_BELOP9","SVAR_TEKST9","selvbetjent flag9"
]
DF_FORM_SVAR = pd.DataFrame(columns=column_names)
#read all answers from file
DF_ALLE_SVAR = pd.read_csv('all_answers.csv')
# read all useridents into the userident field
DF_FORM_SVAR['brukerident'] = DF_ALLE_SVAR['USERIDENTS']
This is the code I wrote to flatten the file, but it's too slow for me, so I hope there is a faster way of doing this
# Loop through all useridents
for i in len(DF_FORM_SVAR):
# Sett the variable userident
KUNDENUMMER = DF_FORM_SVAR["brukerident"][i]
# Loop through all 9 questions and fill them out.
for j in range(9):
# Get the spesific question to fill out for this user
DF_SVAR_RUNDE = DF_ALLE_SVAR.loc[DF_ALLE_SVAR['FORMAL_ART_PROD_NAVN']==FORMAL_INFO[j]]
k = j 1
# check if question is filled out.
if len(DF_SVAR_RUNDE['FORMAL_ART_SPORSMAL_TEKST'].loc[DF_SVAR_RUNDE['FK_BANKKUNDE']==KUNDENUMMER]):
DF_FORM_SVAR['Spørsmål' str(k)][i] = DF_SVAR_RUNDE['FORMAL_ART_SPORSMAL_TEKST'].loc[DF_SVAR_RUNDE['FK_BANKKUNDE']==KUNDENUMMER].iloc[0]
DF_FORM_SVAR['tid' str(k)][i] = DF_SVAR_RUNDE['SVAR_TID'].loc[DF_SVAR_RUNDE['FK_BANKKUNDE']==KUNDENUMMER].iloc[0]
DF_FORM_SVAR['SVAR_BELOP' str(k)][i] = DF_SVAR_RUNDE['SVAR_BELOP'].loc[DF_SVAR_RUNDE['FK_BANKKUNDE']==KUNDENUMMER].iloc[0]
DF_FORM_SVAR['SVAR_TEKST' str(k)][i] = DF_SVAR_RUNDE['SVAR_TEKST'].loc[DF_SVAR_RUNDE['FK_BANKKUNDE']==KUNDENUMMER].iloc[0]
DF_FORM_SVAR['svar j/n' str(k)][i] = DF_SVAR_RUNDE['SVAR_JN'].loc[DF_SVAR_RUNDE['FK_BANKKUNDE']==KUNDENUMMER].iloc[0]
DF_FORM_SVAR['selvbetjent flag' str(k)][i] = DF_SVAR_RUNDE['SELVBETJENT_FLG'].loc[DF_SVAR_RUNDE['FK_BANKKUNDE']==KUNDENUMMER].iloc[0]
CodePudding user response:
pivot might do what you need
import pandas as pd
import io
long_df = pd.read_csv(io.StringIO(
"""
userident,qustion,time,answer j/n,amount,text,flag
1,FMTA DYN 01 - PERSON,13:00,j,14,some info,0
1,FMTA DYN 02 - PERSON,13:00,j,14,some info,0
1,FMTA DYN 03 - PERSON,13:00,j,14,some info,0
2,FMTA DYN 01 - PERSON,13:00,j,14,some info,0
2,FMTA DYN 02 - PERSON,13:00,j,14,some info,0
2,FMTA DYN 03 - PERSON,13:00,j,14,some info,0
3,FMTA DYN 01 - PERSON,13:00,j,14,some info,0
3,FMTA DYN 02 - PERSON,13:00,j,14,some info,0
3,FMTA DYN 03 - PERSON,13:00,j,14,some info,0"""
))
wide_df = long_df.pivot(
index='userident',
columns='qustion',
)
#collapse multiindex columns stolen from
#https://stackoverflow.com/questions/14507794/pandas-how-to-flatten-a-hierarchical-index-in-columns
wide_df.columns = [' '.join(col).strip() for col in wide_df.columns.values]
wide_df
Output
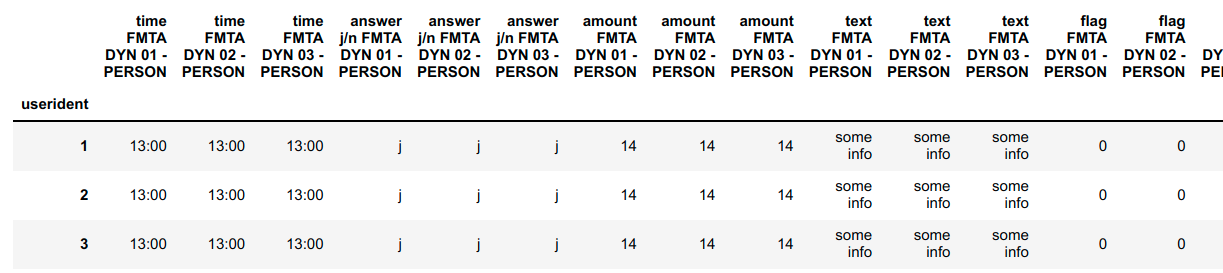
Then you can access the time of the first question for the 1-st person like this
wide_df.loc[1,'time FMTA DYN 01 - PERSON']
CodePudding user response:
Thanks for the tip about pivoting my table, it didn't quite work out for me. I ended up solving it like this:
# Setting up merged dataframe
DF_MERGED = pd.DataFrame()
DF_MERGED['FK_BANKKUNDE'] = DF_ALLE_SVAR_KUN_BRUKERIDENTER['FK_BANKKUNDE']
for i in range(len(FORMAL_INFO)):
j = i 1
DF_TEMP_TABLE = DF_ALLE_SVAR.loc[DF_ALLE_SVAR['FORMAL_ART_PROD_NAVN']==FORMAL_INFO[i]]
DF_MERGED = pd.merge(DF_MERGED, DF_TEMP_TABLE, how='left', on=['FK_BANKKUNDE'],suffixes=('','_' str(j)))