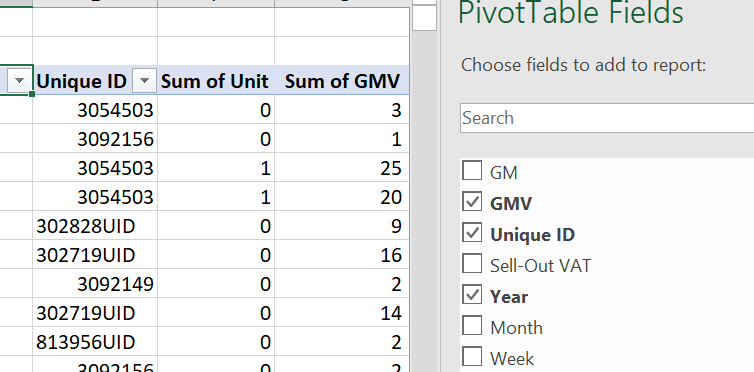
I am having an excel workbook with a sheet containing some pivoted data.
Since the data is in a tabular format, I am able to read it into a dataframe. However, the pandas.read_excel() is able to read only those columns that are present in the pivot table.
I would also want to read/unhide/select the columns that are no part of the pivot table yet.
Is there a way by which I can do this in pandas or any utility in Python?
pandas.melt() doesn't seem to be able to help here. Attaching a snip below.
CodePudding user response:
I'd suggest importing the source data (ie the source range for the pivot) and doing the pivot and aggregations in pandas so you have access to full data set that you need.
CodePudding user response:
not enough rep to comment ; is the source data of the pivot contained in the same workbook? i would read that instead.