I have this dataframe below, but the column "Column_2" have str and date together. How to separate that?
data = {'Column_1': ["foo","bar","foo","foo","bar"],
'Column_2': ["PAID_202109_ASD","DENIED_202109_ASD", "202108_APPROVED_DSA",
"AUTHORIZED_202107_qtd_DSA","202107_AUTHORIZED_ASD"]}
df = pd.DataFrame(data)
>>> df
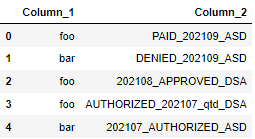
expected result:
>>> df
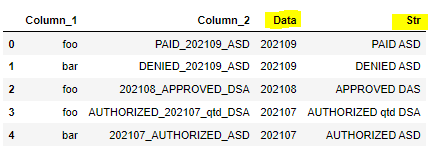
CodePudding user response:
With extract and replace:
df["Data"] = df["Column_2"].str.extract("(\d )")
df["Str"] = df['Column_2'].str.replace("(\d_) "," ", regex=True).str.strip()
>>> df
Column_1 Column_2 Data Str
0 foo PAID_202109_ASD 202109 PAID ASD
1 bar DENIED_202109_ASD 202109 DENIED ASD
2 foo 202108_APPROVED_DSA 202108 APPROVED DSA
3 foo AUTHORIZED_202107_qtd_DSA 202107 AUTHORIZED qtd DSA
4 bar 202107_AUTHORIZED_ASD 202107 AUTHORIZED ASD
CodePudding user response:
First explode your Column_2 then create your 2 columns:
out = df['Column_2'].str.split('_').explode()
mask = out.str.isdigit() # or .str.fullmatch('\d{6}')
df['Data'] = out[mask]
df['Str'] = out[~mask].groupby(level=0).apply(' '.join)
print(df)
# Output:
Column_1 Column_2 Data Str
0 foo PAID_202109_ASD 202109 PAID ASD
1 bar DENIED_202109_ASD 202109 DENIED ASD
2 foo 202108_APPROVED_DSA 202108 APPROVED DSA
3 foo AUTHORIZED_202107_qtd_DSA 202107 AUTHORIZED qtd DSA
4 bar 202107_AUTHORIZED_ASD 202107 AUTHORIZED ASD
I used str.isdigit() to determine if the row is a number or not. You can also use something like str.fullmatch('\d{6}').
CodePudding user response:
df["Str"] =df['Column_2'].str.replace('[\_]',' ', regex=True).str.replace('\d \s ','', regex=True)#First replace - with nothing and all digits followed by space with nothing
df["data"] =df['Column_2'].str.replace('[^\d]',' ', regex=True).str.strip()#Replace everything except digit
Column_1 Column_2 Str data
0 foo PAID_202109_ASD PAID ASD 202109
1 bar DENIED_202109_ASD DENIED ASD 202109
2 foo 202108_APPROVED_DSA APPROVED DSA 202108
3 foo AUTHORIZED_202107_qtd_DSA AUTHORIZED qtd DSA 202107
4 bar 202107_AUTHORIZED_ASD AUTHORIZED ASD 202107