ID What color is this item? What color is this item?_2 What is the shape of this item? What is the shape of this item?_2 size
55 red blue circle triangle small
83 blue yellow circle NA large
78 red yellow square circle large
43 green NA square circle small
29 yellow green circle triangle medium
I would like to get a frequency table like this:
Variable Level Freq Percent
color blue 2 22.22
red 2 22.22
yellow 3 33.33
green 2 22.22
total 9 100.00
shape circle 5 50.0
triangle 3 30.0
square 2 20.0
total 10 100.0
size small 2 33.3
medium 2 33.3
large 2 33.3
total 6 100.0
But I am having trouble matching the names of my columns when I try to convert to long since they are long strings. From a previous question, I know I can do something like:
options(digits = 3)
df1 <- df2 %>%
pivot_longer(
-ID,
names_to = "Question",
values_to = "Response"
) %>%
mutate(Question = str_extract(Question, '')) %>%
group_by(Question, Response) %>%
count(Response, name = "Freq") %>%
na.omit() %>%
group_by(Question) %>%
mutate(Percent = Freq/sum(Freq)*100) %>%
group_split() %>%
adorn_totals() %>%
bind_rows() %>%
mutate(Response = ifelse(Response == last(Response), last(Question), Response)) %>%
mutate(Question = ifelse(duplicated(Question) |
Question == "Total", NA, Question))
But I'm having trouble finding the right regular expression to put in the line:
mutate(Question = str_extract(Question, '')) %>%
If anyone knows another way to do this that would be great as well!
CodePudding user response:
If the intention is to extract a custom list of words, we could paste the elements together to create a single string and use that as regex in str_extract
library(dplyr)
library(tidyr)
library(janitor)
library(stringr)
library(flextable)
pat_words <- c("color", "shape", "size")
out <- df %>%
pivot_longer(
-ID,
names_to = "Question",
values_to = "Response"
) %>% mutate(Question = str_extract(Question, str_c(pat_words, collapse="|"))) %>% group_by(Question, Response) %>%
count(Response, name = "Freq") %>%
na.omit() %>%
group_by(Question) %>%
mutate(Percent = round(Freq/sum(Freq)*100, 2)) %>%
group_split() %>%
adorn_totals() %>%
bind_rows() %>%
mutate(Response = ifelse(Response == last(Response), last(Question), Response)) %>%
mutate(Question = ifelse(duplicated(Question) |
Question == "Total", NA, Question)) %>%
as.data.frame
flextable(out)
-output
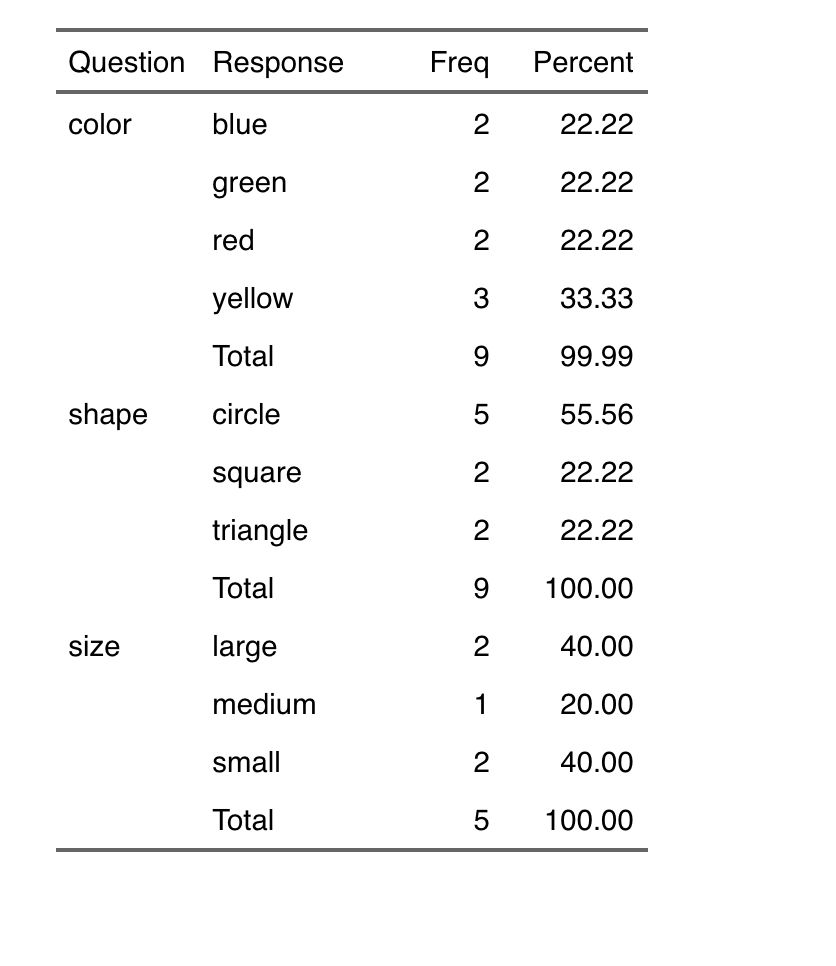
data
df <- structure(list(ID = c(55L, 83L, 78L, 43L, 29L), `What color is this item?` = c("red",
"blue", "red", "green", "yellow"), `What color is this item?_2` = c("blue",
"yellow", "yellow", NA, "green"), `What is the shape of this item?` = c("circle",
"circle", "square", "square", "circle"), `What is the shape of this item?_2` = c("triangle",
NA, "circle", "circle", "triangle"), size = c("small", "large",
"large", "small", "medium")), class = "data.frame", row.names = c(NA,
-5L))
CodePudding user response:
First of all, you should use more proper names for coding.
names(dat)[2:5] <- paste0(rep(c('color.', 'shape.'), each=2), 1:2)
Now we easily may bring the data into long format.
dat_l <- reshape(dat, 2:5, direction='long', idvar='ID')
After that we could use the table() function in base R and its relatives,
vars <- names(dat_l)[c("size", "color", "shape")]
tbl <- lapply(vars, \(x) table(dat_l[, x]) |>
(\(Freq) cbind(Freq=addmargins(Freq),
Percent=addmargins(proportions(Freq))*100))() |>
round(2)) |>
setNames(vars)
to get a nice table for the console.
tbl
# $size
# Freq Percent
# large 4 40
# medium 2 20
# small 4 40
# Sum 10 100
#
# $color
# Freq Percent
# blue 2 22.22
# green 2 22.22
# red 2 22.22
# yellow 3 33.33
# Sum 9 100.00
#
# $shape
# Freq Percent
# circle 5 55.56
# square 2 22.22
# triangle 2 22.22
# Sum 9 100.00
# [1] "R version 4.1.2 (2021-11-01)"
Data
dat <- structure(list(ID = c(55L, 83L, 78L, 43L, 29L), What.color.is.this.item. = c("red",
"blue", "red", "green", "yellow"), What.color.is.this.item._2 = c("blue",
"yellow", "yellow", NA, "green"), What.is.the.shape.of.this.item. = c("circle",
"circle", "square", "square", "circle"), What.is.the.shape.of.this.item._2 = c("triangle",
NA, "circle", "circle", "triangle"), size = c("small", "large",
"large", "small", "medium")), class = "data.frame", row.names = c(NA,
-5L))
CodePudding user response:
Its necessary to make assumptions about the contents of the columns (appl), i.e. give the important keywords.
Then create a dataframe based on the columns
appl <- sapply( c("color","shape","size"), function(x) grep(x, colnames(dat)) )
data.frame( do.call( rbind, sapply( seq_along(appl), function(x){
tbl <- table(unlist( dat[,appl[[x]]] ));
rbind( cbind( Variable=names(appl[x]), Freq=tbl, Percent=round( tbl/sum(tbl)*100, digits=2 ) ),
cbind( Variable=names(appl[x]), sum(tbl), sum(tbl/sum(tbl)*100) ) ) } ) ) )
Variable Freq Percent
blue color 2 22.22
green color 2 22.22
red color 2 22.22
yellow color 3 33.33
X color 9 100
circle shape 5 55.56
square shape 2 22.22
triangle shape 2 22.22
X.1 shape 9 100
large size 2 40
medium size 1 20
small size 2 40
X.2 size 5 100
Data
dat <- structure(list(ID = c(55L, 83L, 78L, 43L, 29L), What.color.is.this.item. = c("red",
"blue", "red", "green", "yellow"), What.color.is.this.item._2 = c("blue",
"yellow", "yellow", NA, "green"), What.is.the.shape.of.this.item. = c("circle",
"circle", "square", "square", "circle"), What.is.the.shape.of.this.item._2 = c("triangle",
NA, "circle", "circle", "triangle"), size = c("small", "large",
"large", "small", "medium")), class = "data.frame", row.names = c(NA,
-5L))