I've been having problems with super slow query in PostgreSQL.
DB ER diagram part focused in this problem:
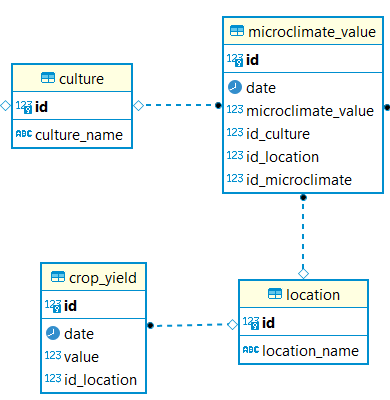
Table culture has 6 records, table microclimate_value has roughly 190k records, table location has 3 records and table crop_yield has roughly 40k records.
Query:
SELECT max(cy.value) AS yield, EXTRACT(YEAR FROM cy.date) AS year
FROM microclimate_value AS mv
JOIN culture AS c ON mv.id_culture = c.id
JOIN location AS l ON mv.id_location = l.id
JOIN crop_yield AS cy ON l.id = cy.id_location
WHERE c.id = :cultureId AND l.id = :locationId
GROUP BY year
ORDER BY year
This query should result with max value from (crop_yield table) for every year for given :cultureId (primary key from culture table) and :locationId (primary key from location table). It would look something like this (yield == value column from crop_yield table):
[
{
"year": 2014,
"yield": 0.0
},
{
"year": 2015,
"yield": 1972.6590590838807
},
{
"year": 2016,
"yield": 3254.6370785040726
},
{
"year": 2017,
"yield": 2335.5804000689095
},
{
"year": 2018,
"yield": 3345.2244602819046
},
{
"year": 2019,
"yield": 3004.7096788680583
},
{
"year": 2020,
"yield": 2920.8721807693764
},
{
"year": 2021,
"yield": 0.0
}
]
Enhancement attempt:
Initially, this query took around 10 minutes, so there is some big problem with optimization or with the query itself. The first thing I did was indexing foreign keys in microclimate_value and crop_yield table, which resulted in far better performance, but the query still takes 2-3 minutes to execute.
Does anyone have any tip on how to improve this? I am open for any tips, including changing the whole schema if needed, considering the fact I'm still learning SQL.
Thanks in advance!
Edit:
- Adding EXPLAIN PSQL
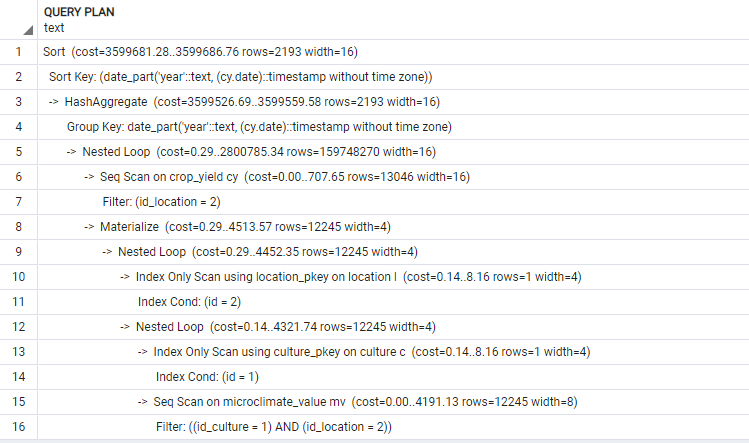
- Adding second EXPLAIN ANALYZE PSQL after adding indexes:

CodePudding user response:
Make some combinations of columns in a single index. I would start with this, to get rid of all the filtering after searching for the data:
CREATE INDEX idx_crop_yield_id_location_year_value ON crop_yield(id_location, (EXTRACT ( YEAR FROM DATE )), value);
CREATE INDEX idx_microclimate_value_id_location_id_culture ON microclimate_value(id_location, id_culture);
Maybe a different order in the columns works better, that's something you have to find out.
I would also leave the unused table "culture" out:
SELECT MAX( cy.VALUE ) AS yield,
EXTRACT ( YEAR FROM cy.DATE ) AS YEAR
FROM
microclimate_value AS mv
JOIN LOCATION AS l ON mv.id_location = l.ID
JOIN crop_yield AS cy ON l.ID = cy.id_location
WHERE
mv.id_culture = : cultureId
AND l.ID = : locationId
GROUP BY YEAR
ORDER BY YEAR;
And after every change in the query or the indexes, run EXPLAIN(ANALYZE, VERBOSE, BUFFERS) again.
CodePudding user response:
Based on your explain analyze there are 10,970 rows of microclimate_value for location=2 and id_culture=1. Also there are 12,316 rows for location=2 in crop_yield.
As there is no other condition for join of those 2 tables, the database has to create in memory a table with 10,970*12,316=135,106,520 rows and then group its results. It might take some time…
I think you are missing some condition in your query. Are you sure there should not be the same date on microclimate_value.date and crop_yield.date? Because, IMHO, without it, the query does not make much sense.
If there's no connection with those dates, then the only information that might be useful in microclimate_value is whether matching location_id=? and culture_id=? exists there:
select
max(value) as max_value,
extract(year from date) as year,
from crop_yield
where location_id=?
and exists(
select 1
from microclimate_value
where location_id=? and culture_id=?
)
group by year
You'll either get results, if they match somewhere, or won't get any. The design of this schema seems questionable.