Using the dataframe I want to create a new one which will contain Zip, Name and a column named Count which will include the count of Name per Zip.
Zip<-c("123245","12345","123245","123456","123456","12345")
Name<-c("Bob","Bob","Bob","Jack","Jack","Mary")
df<-data.frame(Zip,Name)
library(dplyr)
df %>%
group_by(Zip) %>%
mutate(Name = cumsum(Name))
expected
Zip Name Count
1 123245 Bob 2
2 12345 Bob 1
3 12345 Mary 1
4 123456 Jack 2
CodePudding user response:
We could use the name argument of count.
count essentially summarise group_by and summarise:
library(dplyr)
df %>%
count(Zip, Name, name= "Count")
Zip Name Count
1 123245 Bob 2
2 12345 Bob 1
3 12345 Mary 1
4 123456 Jack 2
CodePudding user response:
Does this solve your problem?
Zip<-c("123245","12345","123245","123456","123456","12345")
Name<-c("Bob","Bob","Bob","Jack","Jack","Mary")
df<-data.frame(Zip,Name)
library(dplyr)
#>
#> Attaching package: 'dplyr'
#> The following objects are masked from 'package:stats':
#>
#> filter, lag
#> The following objects are masked from 'package:base':
#>
#> intersect, setdiff, setequal, union
df %>%
group_by(Zip, Name) %>%
summarise(Count = n())
#> `summarise()` has grouped output by 'Zip'. You can override using the `.groups` argument.
#> # A tibble: 4 × 3
#> # Groups: Zip [3]
#> Zip Name Count
#> <chr> <chr> <int>
#> 1 123245 Bob 2
#> 2 12345 Bob 1
#> 3 12345 Mary 1
#> 4 123456 Jack 2
Created on 2021-12-22 by the reprex package (v2.0.1)
--
Quick speed benchmark:
library(tidyverse)
library(microbenchmark)
Zip<-c("123245","12345","123245","123456","123456","12345")
Name<-c("Bob","Bob","Bob","Jack","Jack","Mary")
df<-data.frame(Zip,Name)
JM <- function(df){
df %>%
group_by(Zip, Name) %>%
summarise(Count = n())
}
JM(df)
#> `summarise()` has grouped output by 'Zip'. You can override using the `.groups` argument.
#> # A tibble: 4 × 3
#> # Groups: Zip [3]
#> Zip Name Count
#> <chr> <chr> <int>
#> 1 123245 Bob 2
#> 2 12345 Bob 1
#> 3 12345 Mary 1
#> 4 123456 Jack 2
TarJae <- function(df){
df %>%
count(Zip, Name, name= "Count")
}
TIC <- function(df){
aggregate(cbind(Count = Zip) ~ Zip Name, df, length)
}
TIC(df)
#> Zip Name Count
#> 1 123245 Bob 2
#> 2 12345 Bob 1
#> 3 123456 Jack 2
#> 4 12345 Mary 1
res <- microbenchmark(JM(df), TIC(df), TarJae(df))
autoplot(res)
#> Coordinate system already present. Adding new coordinate system, which will replace the existing one.
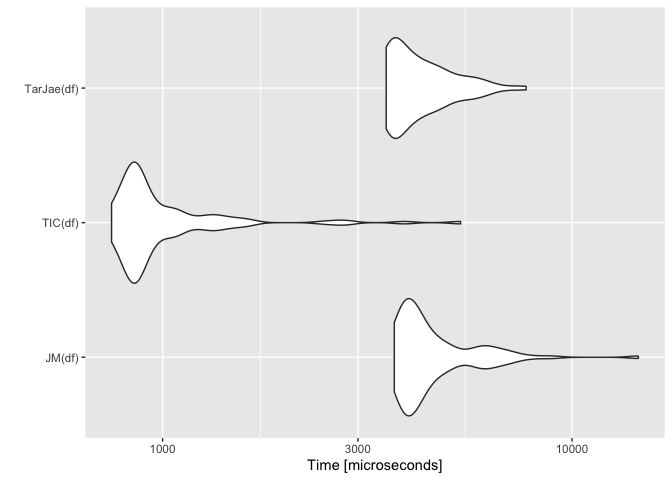
Created on 2021-12-22 by the reprex package (v2.0.1)
CodePudding user response:
A base R option using aggregte
> aggregate(cbind(Count = Zip) ~ Zip Name, df, length)
Zip Name Count
1 123245 Bob 2
2 12345 Bob 1
3 123456 Jack 2
4 12345 Mary 1