I have a dataset of 50 samples and divided that into training and testing datasets. I applied SVM to the training dataset and predicted a model.
Below, you can find svm column from training data and Predicted column from testing data.
data <- structure(list(Samples = c("Sample1", "Sample2", "Sample3", "Sample4",
"Sample5", "Sample6", "Sample7", "Sample8", "Sample9", "Sample10",
"Sample11", "Sample12", "Sample13", "Sample14", "Sample15", "Sample16",
"Sample17", "Sample18", "Sample19", "Sample20", "Sample21", "Sample22",
"Sample23", "Sample24", "Sample25", "Sample26", "Sample27", "Sample28",
"Sample29", "Sample30", "Sample31", "Sample32", "Sample33", "Sample34",
"Sample35", "Sample36", "Sample37", "Sample38", "Sample39", "Sample40",
"Sample41", "Sample42", "Sample43", "Sample44", "Sample45", "Sample46",
"Sample47", "Sample48", "Sample49"), svm = c("typeA", "typeA",
"typeA", "typeB", "typeB", "typeB", "typeB", "typeB", "typeA",
"typeB", "typeA", "typeB", "typeA", "typeB", "typeA", "typeB",
"typeB", "typeB", "typeA", "typeA", "typeB", "typeA", "typeB",
"typeA", "typeB", "typeA", "typeA", "typeA", "typeA", "typeA",
"typeA", "typeB", "typeB", "typeB", "typeB", "typeB", "typeB",
"typeB", "typeA", "typeB", "typeA", "typeB", "typeB", "typeA",
"typeA", "typeA", "typeA", "typeA", "typeB"), Predicted = c("typeA",
"typeA", "typeA", "typeB", "typeB", "typeB", "typeB", "typeB",
"typeA", "typeB", "typeA", "typeA", "typeA", "typeB", "typeA",
"typeB", "typeB", "typeB", "typeA", "typeA", "typeB", "typeA",
"typeB", "typeA", "typeB", "typeA", "typeA", "typeA", "typeA",
"typeA", "typeA", "typeB", "typeB", "typeB", "typeB", "typeA",
"typeB", "typeB", "typeA", "typeA", "typeB", "typeB", "typeB",
"typeA", "typeA", "typeA", "typeA", "typeA", "typeB")), row.names = c(NA,
-49L), class = "data.frame")
And I added pred2 column by doing like below:
data$pred2 <- ifelse(data$svm=="typeA", 1, 0)
I used pROC package to get the AUC.
library(pROC)
res.roc <- roc(data$Predicted, data$pred2)
plot.roc(res.roc, print.auc = TRUE, main="")
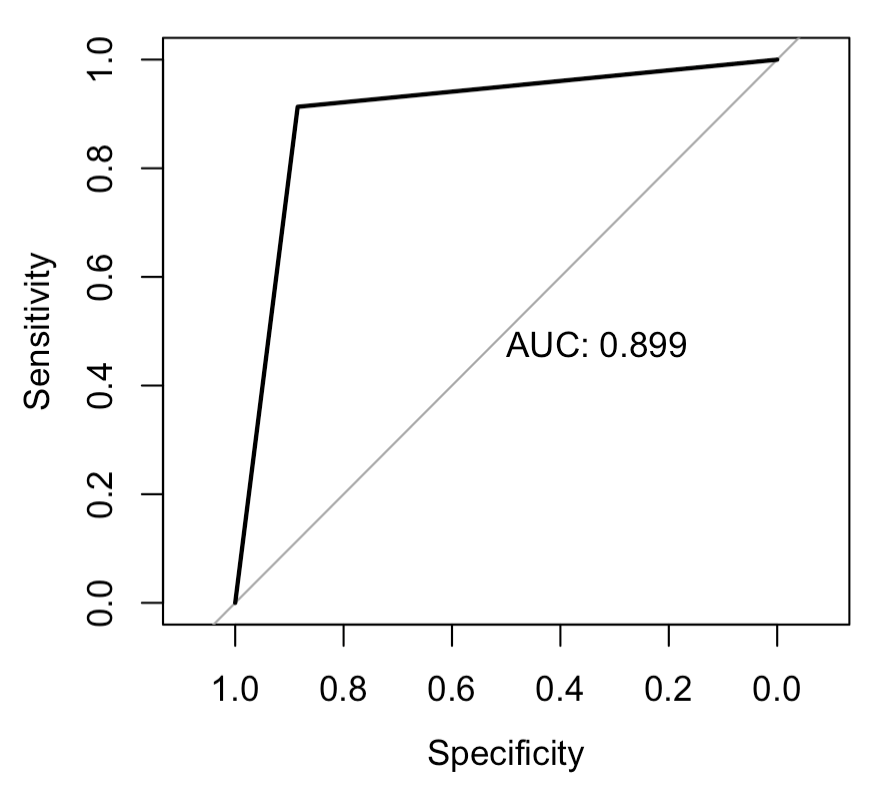
I have seen several posts, which tell that AUC (Area under the curve) tells better about the performance of the model than Accuracy.
I'm confused whether the way I calculated AUC is truly an AUC or Accuracy? Can anyone tell whether this is right or not? Is this enough to check the performance of the model?
CodePudding user response:
I think the question would be better posed to Cross Validated, but accuracy != AUC.
Here's an article that describes the differences and some other, perhaps better, metrics for evaluating the performance of machine learning algorithms: https://neptune.ai/blog/f1-score-accuracy-roc-auc-pr-auc
The short of it is that accuracy requires choosing a cutoff, whereas AUC does not.
The pROC package uses the trapezoid rule to calculate AUC. Check the help for the pROCH::auc function, it has lots of information and references.