I have a table called Product. It has column called colors. It contains data as follows:
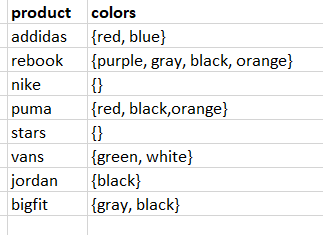
The data type for colors is varchar. The database contains large product values (almost 2 hundred) , and same applies to colors. Now I need to write an sql query script to find top 2 products having largest variation in colors.
CodePudding user response:
You need to split and count the colors for each product(brand):
SELECT products, colors
FROM (
SELECT
*,
DENSE_RANK() OVER (ORDER BY (
SELECT COUNT(DISTINCT LTRIM(RTRIM([value])))
FROM STRING_SPLIT(SUBSTRING(colors, 2, LEN(colors) - 2), ',')
) DESC
) AS rank
-- FROM YourTable
FROM (VALUES
('adidas', '{red, blue, black}'),
('puma', '{red, green, blue, orange}'),
('nike', '{red, green}')
) product (products, colors)
) t
WHERE rank <= 2
Result:
products colors
----------------------------------
puma {red, green, blue, orange}
adidas {red, blue, black}
If you need to count the colors, simply add one additional column:
SELECT products, colors
FROM (
SELECT
*,
(
SELECT COUNT(DISTINCT LTRIM(RTRIM([value])))
FROM STRING_SPLIT(SUBSTRING(colors, 2, LEN(colors) - 2), ',')
) AS [count]
FROM (VALUES
('adidas', '{red, blue, black, blue, red}'),
('puma', '{red, green, blue}'),
('nike', '{red, green}')
) product (products, colors)
) t
WHERE [count] > 2
CodePudding user response:
WITH CTE(PRODUCT,COLOR) AS
(
SELECT 'ADIDAS','{RED,BLUE}' UNION ALL
SELECT 'REEBOK','{PURPLE,GRAY,BLACK,ORANGE}' UNION ALL
SELECT 'NIKE','{}'UNION ALL
SELECT 'PUMA','{RED,BLACK,ORANGE}'
)
SELECT TOP 2 C.PRODUCT,C.COLOR,LEN(C.COLOR)XX
FROM CTE AS C
ORDER BY XX DESC
Could you please try if the above is suitable for you