I'm trying to find a way to do a more advanced group by aggregate in pandas. For example:
d = {'name': ['a', 'a', 'b', 'b', 'b', 'c', 'd', 'e'], 'amount': [2, 5, 2, 3, 7, 2, 4, 1]}
df = pd.DataFrame(data=d)
df_per_category = df.groupby(['name']) \
.agg({'amount': ['count', 'sum']}) \
.sort_values(by=[('amount', 'count')], ascending=False)
df_per_category[('amount', 'sum')].plot.barh()
df_per_category
Produces:
| amount | ||
|---|---|---|
| count | sum | |
| Name | ||
| b | 3 | 12 |
| a | 2 | 7 |
| c | 1 | 2 |
| d | 1 | 4 |
| e | 1 | 1 |
When you have a dataset where 70% of items have just one count and 30% have multiple counts it would be nice if you could group the 70%. At first to begin simple, simply group all the records that have just one count and put them under a name like other. So the result would look like:
| amount | ||
|---|---|---|
| count | sum | |
| Name | ||
| b | 3 | 12 |
| a | 2 | 7 |
| other | 3 | 7 |
Is there a panda's way to do this? Right now I'm thinking of just looping trough my aggregate result and creating a new dataframe manually.
Current solution:
name = []
count = []
amount = []
aggregates = {
5: [0, 0],
10: [0, 0],
25: [0, 0],
50: [0, 0],
}
l = list(aggregates)
first_aggregates = l
last_aggregate = l[-1] 1
aggregates.update({last_aggregate: [0, 0]})
def aggregate_small_values(c):
n = c.name
s = c[('amount', 'sum')]
c = c[('amount', 'count')]
if c <= 2:
if s < last_aggregate:
for a in first_aggregates:
if s <= a:
aggregates[a][0] = c
aggregates[a][1] = s
break
else:
aggregates[last_aggregate][0] = c
aggregates[last_aggregate][1] = s
else:
name.append(n)
count.append(c)
amount.append(s)
df_per_category.apply(aggregate_small_values, axis=1)
for a in first_aggregates:
name.append(f'{a} and smaller')
count.append(aggregates[a][0])
amount.append(aggregates[a][1])
name.append(f'{last_aggregate} and bigger')
count.append(aggregates[last_aggregate][0])
amount.append(aggregates[last_aggregate][1])
df_agg = pd.DataFrame(index=name, data={'count': count, 'amount': amount})
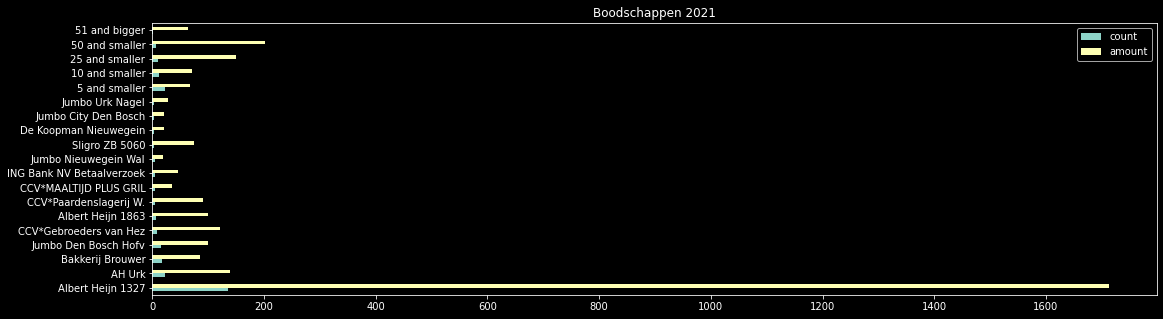
df_agg.plot.barh(title='Boodschappen 2021')
df_agg
yields something like:
CodePudding user response:
If need replace name by other if counts is 1 use Series.duplicated with keep=False:
df.loc[~df['name'].duplicated(keep=False), 'name'] = 'other'
print (df)
name amount
0 a 2
1 a 5
2 b 2
3 b 3
4 b 7
5 other 2
6 other 4
7 other 1
If need replace by percenteges, here below 20% is set other use Series.value_counts with normalize=True and then use Series.map for mask with same size like original df:
s = df['name'].value_counts(normalize=True)
print (s)
b 0.375
a 0.250
d 0.125
e 0.125
c 0.125
Name: name, dtype: float64
df.loc[df['name'].map(s).lt(0.2), 'name'] = 'other'
print (df)
name amount
0 a 2
1 a 5
2 b 2
3 b 3
4 b 7
5 other 2
6 other 4
7 other 1
For filter by counts, here below 3:
s = df['name'].value_counts()
print (s)
b 3
a 2
d 1
e 1
c 1
Name: name, dtype: int64
df.loc[df['name'].map(s).lt(3), 'name'] = 'other'
print (df)
name amount
0 other 2
1 other 5
2 b 2
3 b 3
4 b 7
5 other 2
6 other 4
7 other 1