I have a dataframe with two columns (time_id and param1). For column 2 (param1) I want to create a boxplot according time.
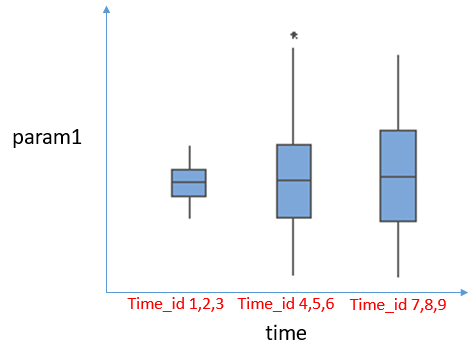
However I want to split it into into three (or n) parts. Which means that there is not only one box in the box plot, but one box per time range. For example (n=3) a box based on the values 20,3,4,21,19 [time 1-3] and a box based on 8,9,18,6,4 [time 4-6] etc.
So the following code creates a boxplot of the entire column.
import pandas as pd
# initialize data of lists.
data = {'time_id':[1,1,2,3,3,4,5,5,5,6,7,8,8,9],
'param1':[20,3,4,21,19,8,9,18,6,4,2,3,7,1]}
# Create DataFrame
df = pd.DataFrame(data)
boxplot = df.boxplot(column='param1')
What is an elegant way to divide the column into three boxes so that the box plot looks like this (exemplary):
CodePudding user response:
I am not sure it is the most elegant way to do it but you can use the function cut() from pandas and the method of dataframe .pivot() :
df["class"]=pd.cut(df['time_id'], bins=3, labels=False)
df = df.drop("time_id", axis=1).pivot(columns="class")
boxplot = df.boxplot()
CodePudding user response:
Since your time series is more or less evenly spaced, I would also go with 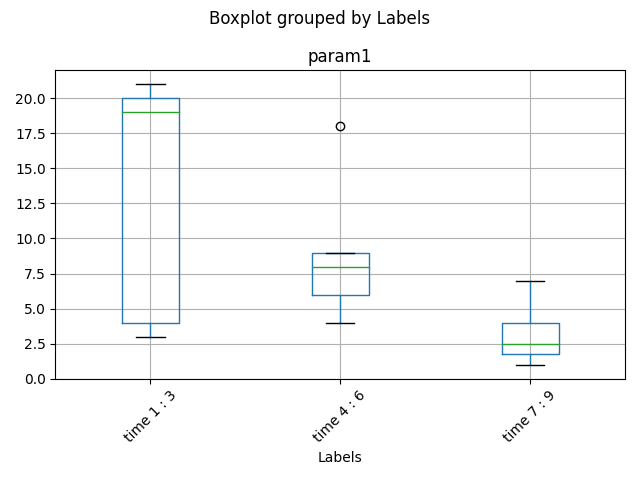
In a real-world example, your time series probably contains float, not integer numbers. These float numbers might be rather long, making the labels also rather annoyingly long. In this case, you can abbreviate their output with
bin_labels = ['time {mini:.2} : {maxi:.2}'.for.... but this wouldn't work with integer arrays.