There are 3 tables in SQL Server with large amount of data, each table contains about 100000 rows. There is one SQL to fetch rows from the three tables. Its performance is very bad.
WITH t1 AS
(
SELECT
LeadId, dbo.get_item_id(Log) AS ItemId, DateCreated AS PriceDate
FROM
(SELECT
t.ID, t.LeadID, t.Log, t.DateCreated, f.AskingPrice
FROM
t
JOIN
f ON f.PKID = t.LeadID
WHERE
t.Log LIKE '%xxx%') temp
)
SELECT COUNT(1)
FROM t1
JOIN s ON s.ItemID = t1.ItemId
When checking its estimated execution plan, I find it uses a nested loop join with large rows. Loot at the screenshot below. The top part in the image return 124277 rows, and the bottom part is executed 124277 times! I guess this is why it is so slow.
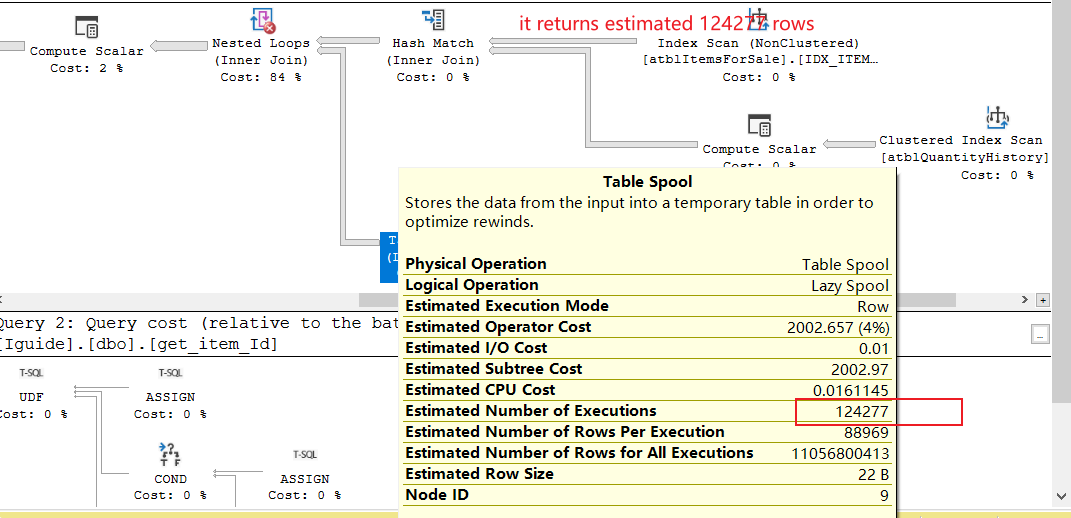
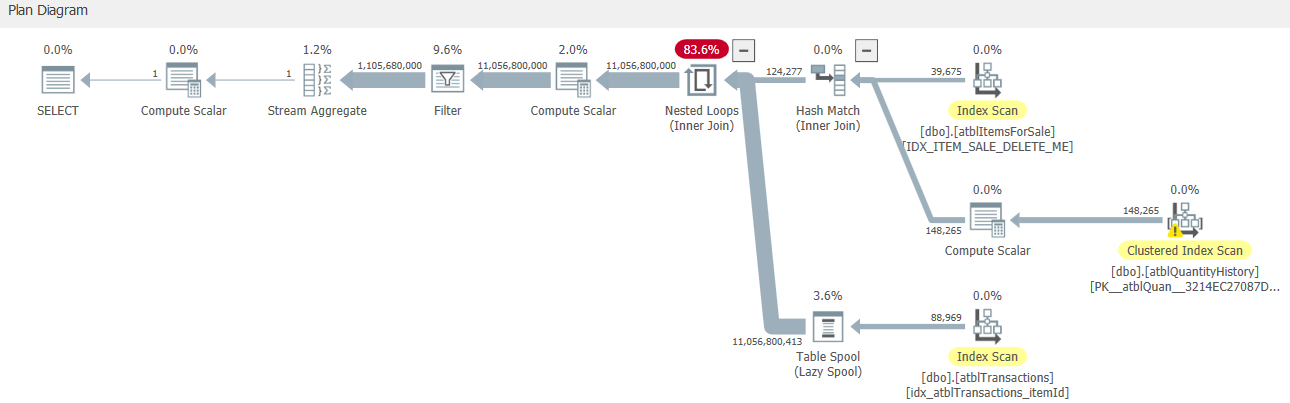
We know that nested loop has big performance issue with large data. How to remove it, and use hash join or other join instead?
Edit: Below is the related function.
CREATE FUNCTION [dbo].[get_item_Id](@message VARCHAR(200))
RETURNS VARCHAR(200) AS
BEGIN
DECLARE @result VARCHAR(200),
@index int
--Sold in eBay (372827580038).
SELECT @index = PatIndex('%([0-9]%)%', @message)
IF(@index = 0)
SELECT @result='';
ELSE
SELECT @result= REPLACE(REPLACE(REPLACE(SUBSTRING(@message, PatIndex('%([0-9]%)%', @message),8000), '.', ''),'(',''),')','')
-- Return the result of the function
RETURN @result
END;
CodePudding user response:
For some reason it has decided to do s cross join t1 then evaluate the function (result aliased as Expr1002) and then do a filter on [s].[ItemID]=[Expr1002] (instead of doing an equi join).
It estimates that it will have 88,969 and 124,277 rows going into the cross join (which means it would produce 11,056,800,413)
Executing the scalar UDF after the cross join an estimated 11 billion times and then filtering the estimated 11 billion rows down does seem crazy. If it was evaluated before the join it would be evaluated much fewer times and would also be an equi join so could also use HASH or MERGE inner joins and just read all tables once without blowing the row count up.
I reproduced this locally and the behaviour changed when the UDF was created WITH SCHEMABINDING - SQL Server can then see that it does not access any tables and is deterministic but I don't know if that is the cause of the current bad plan.
I strongly suggest getting rid of this scalar function and replacing it with an inline version though as non inline scalar functions have many well known performance problems.
The new function would be
CREATE FUNCTION get_item_Id_inline (@message VARCHAR(200))
RETURNS TABLE
AS
RETURN
(SELECT item_Id = CASE
WHEN PatIndex('%([0-9]%)%', @message) = 0 THEN ''
ELSE REPLACE(REPLACE(REPLACE(SUBSTRING(@message, PatIndex('%([0-9]%)%', @message), 8000), '.', ''), '(', ''), ')', '')
END)
and rewritten query
WITH t1
AS (SELECT t.LeadID,
i.item_Id AS ItemId,
t.DateCreated AS PriceDate
FROM t
CROSS apply dbo.get_item_Id_inline(t.Log) i
JOIN f
ON f.PKID = t.LeadID
WHERE t.Log LIKE '%xxx%')
SELECT COUNT(1)
FROM t1
JOIN s
ON s.ItemID = t1.ItemId
there may still be room for some additional optimisations but this will be orders of magnitudes better than your current execution plan (as that is catastrophically bad).
CodePudding user response:
To optimize the query, do the following:
- Take the "t.Log LIKE condition '% xxx%'" to a more internal selection. This allows fewer records to be included in the join.
- Do not use "likes".
- Remove the top selection in your view.
- Optimize the "dbo.get_item_id" function or use alternative solutions because comparisons within this function are also very time consuming.
Finally, your query will look like the following code:
WITH t1 AS
(
SELECT
u.ID
, u.LeadID as LeadId
, dbo.get_item_id(u.Log) AS ItemId
, u.DateCreated AS PriceDate
, f.AskingPrice
FROM
(select ID, LeadID, Log, DateCreated from t WHERE Log LIKE '%xxx%')u
JOIN
f ON f.PKID = u.LeadID
)
SELECT COUNT(1)
FROM t1
JOIN s ON s.ItemID = t1.ItemId'
CodePudding user response:
"COUNT" over a big result is never a good idea. Additionally you have LIKE '%xxx%', which always results into a full scan and cannot be predicted by the optimization engine.
It know, it is a costly way, but I would redesign the application. Maybe adding some trigger and de-normalizing the data structure could be a good solution.
CodePudding user response:
In case you'd still want to use the get_item_Id UDF.
Here's a golf-coded deterministic version of it.
CREATE FUNCTION [dbo].[get_item_Id](@message VARCHAR(200))
RETURNS VARCHAR(20)
WITH SCHEMABINDING
AS
BEGIN
DECLARE @str VARCHAR(20);
SET @str = SUBSTRING(@message, PATINDEX('%([0-9]%',@message) 1, 20);
IF @str NOT LIKE '[0-9]%[0-9])%' RETURN NULL;
RETURN LEFT(@str, PATINDEX('%[0-9])%', @str));
END;