I have the following function to scrape a webpage.
def parse(link: str, list_of_samples: list, index: int) -> None:
# Some code to scrape the webpage (link is given)
# The code will generate a list of strings, say sample
list_of_samples[index] = sample
I have another script that calls the above script for all URLs present in a list
def call_that_guy(URLs: list) -> list:
samples = [None for i in range(len(URLs))]
for i in range(len(URLs)):
parse(URLs[i], samples, i)
return samples
Some other function that calls the above function
def caller() -> None:
URLs = [url_1, url_2, url_3, ..., url_n]
# n will not exceed 12
samples = call_thay_guy(URLs)
print(samples)
# Prints the list of samples, but is taking too much time
One thing I noticed is that the parse function is taking around 10s to parse a single webpage (I am using Selenium). So, parsing all the URLs present in the list, it is taking around 2 minutes. I want to speed it up, probably using multithreading.
I tried doing the following instead.
import threading
def call_that_guy(URLs: list) -> list:
threads = [None for i in range(len(URLs))]
samples = [None for i in range(len(URLs))]
for i in range(len(URLs)):
threads[i] = threading.Thread(target = parse, args = (URLs[i], samples, i))
threads[i].start()
return samples
But, when I printed the returned value, all of its contents were None.
What am I trying to Achieve:
I want to asynchronously Scrape a list of URLs and populate the list of samples. Once the list is populated, I have some other statements to execute (they should execute only after samples is populated, else they'll cause Exceptions). I want to scrape the list of URLs faster (asynchronously is allowed) instead of scraping them one after another.
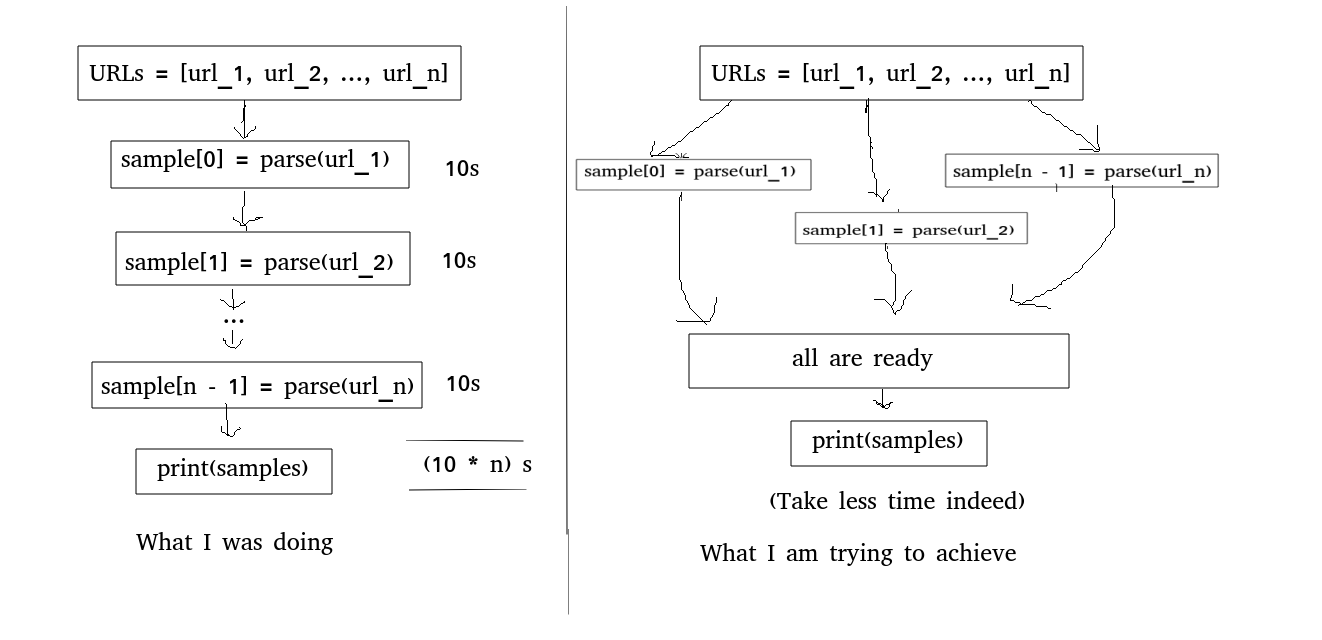
(I can explain something more clearly with image)
CodePudding user response:
Why don't you use concurrent.futures module?
Here is a very simple but super fast code using concurrent.futures:
import concurrent.futures
def scrape_url(url):
print(f'Scraping {url}...')
scraped_content = '<html>scraped content!</html>'
return scraped_content
urls = ['https://www.google.com', 'https://www.facebook.com', 'https://www.youtube.com']
with concurrent.futures.ThreadPoolExecutor(max_workers=3) as executor:
results = executor.map(scrape_url, urls)
print(list(results))
# Expected output:
# ['<html>scraped content!</html>', '<html>scraped content!</html>', '<html>scraped content!</html>']
If you want to learn threading, I recommend watching this short tutorial: https://www.youtube.com/watch?v=IEEhzQoKtQU
Also note that this is not multiprocessing, this is multithreading and the two are not the same. If you want to know more about the difference, you can read this article: https://realpython.com/python-concurrency/
Hope this solves your problem.