I have a data set filled with invoices columns including:
- CaseID
- Customer
- Supplier
- Part Number
- Cost.
This data set includes Charges and Credits. I want to remove the Credits and the Charges they credited from DataFrame. I'd like to remove the rows in original that are credits and the charges they pertain to. But there are some instances where a transaction was charged twice on accident so the information is a duplicate. I do not want to remove the duplicate if there is a credit since the duplicate will need a credit as well.
I have the original df. I created a charge df where it is all rows with Cost > 0 from the original. I created a credit df where it is all rows with Cost < 0 from the original.
My question is if I use df1[~df1.isin(df2)].dropna() or in this case:
invoiced[~invoiced.isin(credits)].dropna()
How do I specify that I only want the row dropped one time? Is it possible?
ex:
invoice =
Case| Part_Number | Cost
111 | 2G | 53.00
112 | 7G | 25.00
112 | 7G | 25.00
113 | 8G | 20.00
113 | 8G | -20.00
114 | 9G | 15.00
115 | 2G | 53.00
115 | 2G | 53.00
115 | 2G | -53.00
Charge =
Case| Part_Number | Cost
111 | 2G | 53.00
112 | 7G | 25.00
112 | 7G | 25.00
113 | 8G | 20.00
114 | 9G | 15.00
115 | 2G | 53.00
115 | 2G | 53.00
Credits =
Case| Part_Number | Cost
113 | 8G | -20.00
115 | 2G | -53.00
Output =
df =
Case| Part_Number | Cost
111 | 2G | 53.00
112 | 7G | 25.00
112 | 7G | 25.00
114 | 9G | 15.00
115 | 2G | 53.00
See how it removed 113 since there was 1 charge and 1 credit but kept (1) of 115 since there were 2 charges and 1 credit.
CodePudding user response:
From my understanding, outputdf is supposed to show which invoice hasn't been paid yet, even if it is a duplicate, correct? I believe this is the code you're looking for and ill explain it in a bit.
dfinvoice = pd.DataFrame(columns=['Case', 'PartNo', 'Cost'],
data=np.array([['111', '2g', 53],
['112', '7g', 25],
['112', '7g', 25],
['113', '8g', 20],
['113', '8g', -20],
['114', '9g', 15],
['115', '2g', 53],
['115', '2g', 53],
['115', '2g', -53]
]))
dfcharge = pd.DataFrame(columns=['Case', 'PartNo', 'Cost'],
data=np.array([['111', '2g', 53],
['112', '7g', 25],
['112', '7g', 25],
['113', '8g', 20],
['114', '9g', 15],
['115', '2g', 53],
['115', '2g', 53]
]))
dfcredits = pd.DataFrame(columns=['Case', 'PartNo', 'Cost'],
data=np.array([['113', '8g', -20],
['115', '2g', -53]
]))
dfowing = pd.DataFrame(columns=['Case', 'PartNo', 'Cost'],
data= np.array([['111', '2g', 53],
['112', '7g', 25],
['112', '7g', 25],
['114', '9g', 15],
['115', '2g', 53]
]))
df = dfinvoice
for x, y in df.iterrows():
for a, b in df.iterrows():
if y[0] == b[0]:
if x != a:
first = int(y[2])
second = int(b[2])
if first > 0 and second < 0:
print(x, y)
print('compared to')
print(a, b)
df = df.drop(x)
df = df.drop(a)
print(df)
dfowing is what the dataframe should look like. I was using that as a reference.
Using a for loop in a for loop you can cross reference you're values. x and a being the index, y and b are the rows of data. in the first if statement I was checking if the invoice numbers matched. in the second if statement I had to make sure that the index didn't match so it would compare itself to the next row, although not exactly necessary. first and last are the the values from the 'cost' column which in my dataframe they were returning as a string and you cant compare integers and strings to check if one is greater or less than 0. in the last if statement check if one is greater than 0 and one is less than 0 and remove that row using the index using df = df.drop() to get rid of each match where an invoice has been charged and then credited.
I'm not the greatest at explaining these things so if anyone wants to edit my explanation feel free :)
CodePudding user response:
Try this:
invoices = pd.DataFrame([['111', '2g', 53],
['112', '7g', 25],
['112', '7g', 25],
['113', '8g', 20],
['113', '8g', -20],
['114', '9g', 15],
['115', '2g', 53],
['115', '2g', 53],
['115', '2g', -53]],
columns=['Case', 'PartNo', 'Cost'])
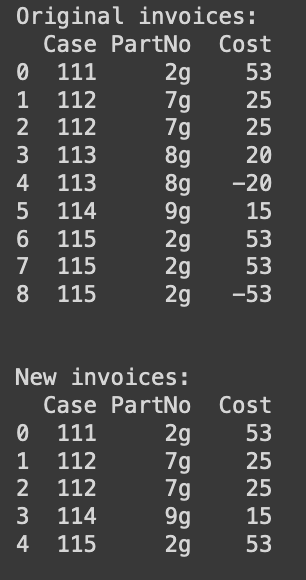
print(f"Original invoices:\n{invoices}\n\n")
newInvoices = invoices.copy()
newInvoices['Charge_Credit'] = 0
for idx, case, part, cost, ch_cr in newInvoices.itertuples():
creditedDf = newInvoices[(newInvoices.Case == case) &
(newInvoices.PartNo == part) &
(newInvoices.Cost == -cost) &
(newInvoices.Charge_Credit != 'remove')]
if len(creditedDf):
newInvoices.loc[creditedDf.iloc[0].name, 'Charge_Credit'] = 'remove'
newInvoices = newInvoices[['Case', 'PartNo', 'Cost']][newInvoices.Charge_Credit != 'remove']
newInvoices.reset_index(drop=True, inplace=True)
print(f"New invoices:\n{newInvoices}\n")