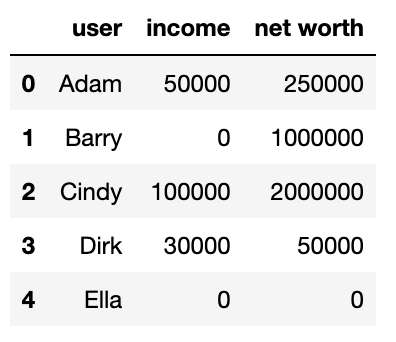
Suppose I have the following dataframe:
import numpy as np
import pandas as pd
df = pd.DataFrame(
{
'user': ['Adam', 'Barry', 'Cindy', 'Dirk', 'Ella'],
'income': [50000, 0, 100000, 30000, 0],
'net worth': [250000, 1000000, 2000000, 50000, 0]
}
)
So far, I've been removing rows based on conditions using the following:
df2 = df[df.income != 0]
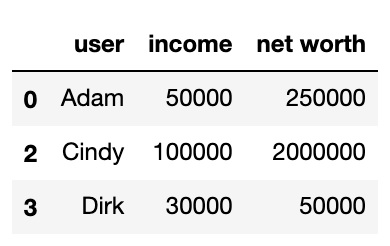
And using multiple conditions like so:
df3 = df[(df['income'] != 0) & (df['net worth'] > 100000)]
Question: Is this the preferred way to drop rows? If not, what is? Is it possible to do this via df.drop and df.loc? What would the syntax be?
CodePudding user response:
.loc creates a subset of the rows you want to keep rather than .drop filter rows you want to remove. drop need the row label (index name).
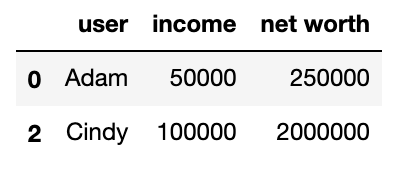
The equivalent of your last filter with drop is:
>>> df.drop(df[~((df['income'] != 0) & (df['net worth'] > 100000))].index)
user income net worth
0 Adam 50000 250000
2 Cindy 100000 2000000
# OR a bit smart:
>>> df.drop(df[(df['income'] == 0) | (df['net worth'] <= 100000)].index)
user income net worth
0 Adam 50000 250000
2 Cindy 100000 2000000
Which syntax do you prefer?