Let's create 2 dataframes, df1 and df2:
import pandas as pd
df1 = pd.DataFrame([["A", "A", "B", "B", "C"], ["a1", "a2", "b1", "b2", "c1"], [10, 10, 20, 20, 30], [1, 5, 6, 3, 4]]).T
df2 = pd.DataFrame([["B", "B", "C", "F"], ["b1", "b3", "c1", "f2"], [30, 30, 40, 40], [8, 3, 5, 2]]).T
df1.columns = df2.columns = ["label1", "label2", "total", "count"]
Please notice, "total" must be the same for each "label1"
I need to merge theses 2 dataframes following these rules :
- All "count" with same "label2" are simply added. ex: in df1, b1=6, in df2, b1=8, when merged, b1=14
- "total" with same "label1" are added (and must be the same for each "label1"). ex: in df1, all B=20, in df2, all B=30, when merged, all B=50
In df3, this is what I'm trying to get:
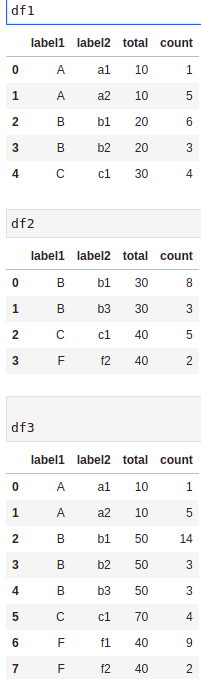
I think I should maybe use pandas.DataFrame.merge, 1 or 2 times, but I don't even understand how to aggregate data. Any clue is appreciated.
CodePudding user response:
Try this:
import pandas as pd
df1 = pd.DataFrame([["A", "A", "B", "B", "C"], ["a1", "a2", "b1", "b2", "c1"], [10, 10, 20, 20, 30], [1, 5, 6, 3, 4]]).T
df2 = pd.DataFrame([["B", "B", "C", "F"], ["b1", "b3", "c1", "f2"], [30, 30, 40, 40], [8, 3, 5, 2]]).T
df1.columns = df2.columns = ["label1", "label2", "total", "count"]
df_both = df1.assign(df=1).append(df2.assign(df=2))
df_lable1 = df_both.drop_duplicates(['label1', 'df']).groupby('label1')['total'].sum().reset_index()
df_lable2 = df_both.groupby('label2')['count'].sum().reset_index()
df3 = df_both[['label1', 'label2']].drop_duplicates(["label1", "label2"]).sort_values(["label1", "label2"])
df3 = df3.merge(df_lable1, on=['label1'], how='left')
df3 = df3.merge(df_lable2, on=['label2'], how='left')
# label1 label2 total count
# 0 A a1 10 1
# 1 A a2 10 5
# 2 B b1 50 14
# 3 B b2 50 3
# 4 B b3 50 3
# 5 C c1 70 9
# 6 F f2 40 2
CodePudding user response:
Merge first then aggregate:
cols = ['label1', 'label2']
prefix = lambda x: x.split('_')[0]
out = df1.merge(df2, on=cols, how='outer').set_index(cols) \
.groupby(by=prefix, sort=False, axis=1).sum().reset_index()
print(out)
# Output
label1 label2 total count
0 A a1 10 1
1 A a2 10 5
2 B b1 50 14
3 B b2 20 3
4 C c1 70 9
5 B b3 30 3
6 F f2 40 2
CodePudding user response:
Try this:
df3 = (
pd.concat([df1, df2])
.pipe(lambda x: (x.assign(total=x['label1'].map(x.groupby('label1')['total'].unique().apply(sum))))
.groupby(['label1', 'label2'])
.agg(total=('total', 'first'), count=('count', 'sum'))
.reset_index()
)
Output:
>>> df3
label1 label2 total count
0 A a1 10 1
1 A a2 10 5
2 B b1 50 14
3 B b2 50 3
4 B b3 50 3
5 C c1 70 9
6 F f2 40 2