I've been trying to exclude all the rows that contain 'shirt' and then from that have the rows that have 'cotton' (case insensitive)
for example:
"Cotton Shirt for sale" - don't include
"Cotton Dress for Sale" - Pass
"dress shirt-V-neck-cotton" -fail
"no words relevant" - Fail (no cotton in it)
"cotton-url click" - pass
My regex:
pattern = re.compile('(?i)^((?!.*shirt).).*(?=.*cotton.*)')
But for some reason my rows in csv still remain on a sentence:
"Stone Italian Yarn Fringe Yoke Cable Cotton Shirt New Look"
my code:
pattern1 = re.compile("(?i)(.*shirt.*)")
with open("sample.csv", 'r', encoding="utf-8") as bigCSV:
csv_reader = csv.reader(bigCSV)
counterWithout = 0
counterCheck = 0
headFlag = True
for row in csv_reader:
if headFlag:
header = row
headFlag = False
if any(pattern.match(line) for line in row)://there is a difference in the number of rows here
if any(pattern1.match(line) for line in row):
print(row)
counterCheck = 1
counterWithout = 1
Help fix regex please
CodePudding user response:
You can use .*(cotton)?.*shirt.*|.*shirt.*(cotton)?.*
It will match every shirt with condition of cotton before or after it. So you can delete every row that satisfy this.
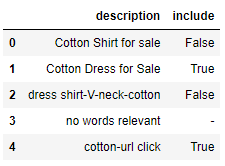
You can now set any remaining rows marked - to False (I find it easier to debug this way, especially if the conditions get more complicated), or you could have started off by initialising the "include" column to False.