I am trying to create a customer journey for period they were active for. The base data is unordered and looks as:
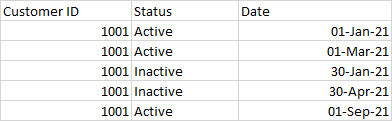
I want to look first for the date when the Status=Active and then the succeeding date when Status=Inactive and the pull in the period and repeat for the next instance of the appearances. the output I am looking for is to create a table that looks as below:
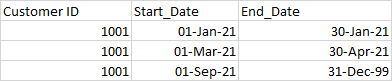
Any pointers on how to do in Teradata SQL would be highly helpful.
CodePudding user response:
Here is the SQL (dbfiddle link):
WITH active_status
AS (SELECT customerid,
Row_number()
OVER (
ORDER BY start_date) id,
start_date
FROM (SELECT customerid,
CASE
WHEN status = 'Active' THEN dt
END "start_date"
FROM cust) x
WHERE start_date IS NOT NULL),
inactive_status
AS (SELECT customerid,
Row_number()
OVER (
ORDER BY end_date) id,
end_date
FROM (SELECT customerid,
CASE
WHEN status = 'Inactive' THEN dt
END "end_date"
FROM cust) x
WHERE end_date IS NOT NULL)
SELECT acta.customerid,
acta.start_date,
COALESCE(inacta.end_date, '2099-12-31') end_date
FROM active_status acta
LEFT OUTER JOIN inactive_status inacta
ON acta.customerid = inacta.customerid
AND acta.id = inacta.id
ORDER BY start_date;
Since Teradata SQL dialect is similar to postgreSQL , I have used it in dbfiddle link . dbfiddle does not support teradata for testing. row_number() analytical function and coalesce() which are the only significant pieces are available in teradata.
CodePudding user response:
As long as there's always a matching 'Inactive' row for every 'Active' row and only the final 'Inactive' might be missing:
select customerid, dt,
-- next 'Inactive' row, "until changed" for last row
lead(case when status = 'Inactive' then dt end, 1, date '9999-12-31')
over (partition by customerid
order by dt)
from cust
-- only return the 'Active' rows
qualify status = 'Active';