Problem
I have a dataframe with image_ids and their respective hash_values. The columns represent the difference of that image_id w.r.t. other image ids as shown below:
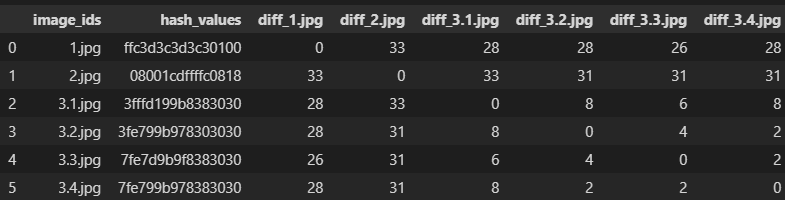
These differences have been calculated to find which images are similar. The images having difference value less than 15 are considered as similar images.
Objective
I want to obtain the dataframe with only unique image_ids i.e., delete the image_ids which are similar and only keep one of them.
Example
As an example, in the dataframe images 1.jpg and 2.jpg are similar as their difference is 33 which is greater than 15 but images 3.1.jpg, 3.2.jpg, 3.3.jpg are similar as their difference values are less than 15.
Desired Output
The desired output should be the dataframe with only the image_ids as 1.jpg, 2.jpg, 3.1.jpg.
3.2.jpg and 3.3.jpg should be deleted as they are similar.
I wrote the below code, but it is removing any image having a similar value i.e., it removes 3.1.jpg, 3.2.jpg, 3.3.jpg all of them from the dataframe.
# For every image_id, find the column values having value < 15 more than once and delete respective rows
def remove_duplicates(df):
for i in range(len(df.image_ids)):
clean_df = df.drop(df[df[f"diff_{df.image_ids[i]}"] < 15].index)
return clean_df
clean_df = remove_duplicates(df)
The output of the code is:

As it can be clearly observed that the image 3.1.jpg is absent in the dataframe whereas it should be present.
How to fix this?
CodePudding user response:
If the difference columns for the images that have been removed isn't needed, dropping that image's difference column is a simple solution.
def remove_duplicates(df):
for i in range(len(df.image_ids)):
# This is the column that we want to drop
col = 'diff_' df[image_ids].iloc[i]
clean_df = df.drop(df[df[f"diff_{df.image_ids[i]}"] < 15].index)
# Dropping the column
clean_df = clean_df.drop(columns=col)
return clean_df
Note: The code might not work as I believe you're deleting all of the similar images at the same time. But I believe you can fix this by only deleting only the image at the current index whilst iterating and not deleting the other images. I didn't do this myself as I didn't understand this line
clean_df = df.drop(df[df[f"diff_{df.image_ids[i]}"] < 15].index)
Still, removing only the current index's image and not the other similar images is a trivial task but I'm too lazy to do that from scartch.
CodePudding user response:
Here what I have come up with. I firmly believe it's not the best idea, but might be a solution to your problem:
import pandas as pd
import re
df = pd.DataFrame({"image_ids": ["1.jpg", "2.jpg", "3.2.jpg", "3.1.jpg", "3_3.jpg"]})
checkList = []
newDf = pd.DataFrame()
for index, row in df.iterrows():
id = row["image_ids"]
m1 = re.search(r"^(\d )\.jpg$", id)
m2 = re.search(r"^(\d )\.(\d )\.jpg$", id)
if m1:
if m1.group(1) in checkList:
continue
else:
checkList.append(m1.group(1))
newDf = newDf.append(row)
elif m2:
if m2.group(1) in checkList:
continue
elif m2.group(2) == "1":
checkList.append(m2.group(1))
newDf = newDf.append(row)
Note that, to have an example data, I wrote df dataframe. You have to change this line to load your dataframe.
Explanation
In this code, I have used regex to extract the id of each image. The first regex will catch the image's name which has a pattern like 5.jpg. The second regex will capture if the image's name is something like 52.3.jpg. Having appended the ids to a variable named checkList, I check if the image id has been selected before.