I have a pandas dataframe that has combinations of two id columns such as this:
| ID1 | ID2 |
|---|---|
| A | B |
| A | C |
| A | D |
| A | E |
| B | C |
| B | D |
| B | E |
| C | D |
| C | E |
| D | E |
| F | H |
| I | K |
| K | J |
| G | F |
| G | H |
| I | J |
Here we have the choose 2 combinations for ABCD, FGH, IJK.
I would like to only keep the rows for the value with the most ID1's for a particular set. For ABCD this would be A, for FGH this would be G, and for IJK this would be I. Resulting in the following:
| ID1 | ID2 |
|---|---|
| A | B |
| A | C |
| A | D |
| A | E |
| I | K |
| G | F |
| G | H |
| I | J |
CodePudding user response:
Assuming you don't know in advance the groups, this could be approached as a graph problem using 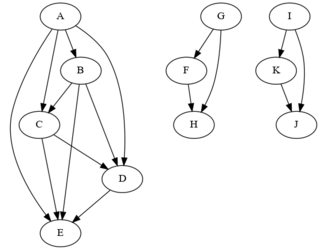
What you need is to find the root of each cluster (see here for the method to find roots).
import networkx as nx
G = nx.from_pandas_edgelist(df, source='ID1', target='ID2',
create_using=nx.DiGraph)
roots = [n for n,d in G.in_degree() if d==0]
df2 = df[df['ID1'].isin(roots)]
output:
ID1 ID2
0 A B
1 A C
2 A D
3 A E
11 I K
13 G F
14 G H
15 I J
CodePudding user response:
Calculate the count of unqiue values in ID1, then inside a list comprehension for each set calculate the index of maximum value, finally use these indices to filter the rows in dataframe
c = df['ID1'].value_counts()
i = [c.reindex([*s]).idxmax() for s in ['ABCB', 'FGH', 'IJK']]
df[df['ID1'].isin(i)]
ID1 ID2
0 A B
1 A C
2 A D
3 A E
11 I K
13 G F
14 G H
15 I J