I am having a data frame of four columns. I want to find the minimum among the first two columns and the last two columns for each row. Code:
np.random.seed(0)
xdf = pd.DataFrame({'a':np.random.rand(1,10)[0]*10,'b':np.random.rand(1,10)[0]*10,'c':np.random.rand(1,10)[0]*10,'d':np.random.rand(1,10)[0]*10,},index=np.arange(0,10,1))
xdf['ab_min'] = xdf[['a','b']].min(axis=1)
xdf['cd_min'] = xdf[['c','d']].min(axis=1)
xdf['minimum'] = xdf['ab_min'].list() xdf['cd_min'].list()
Expected answer:
xdf['minimum']
0 [ab_min,cd_min]
1 [ab_min,cd_min]
2 [ab_min,cd_min]
3 [ab_min,cd_min]
Present answer:
AttributeError: 'Series' object has no attribute 'list'
CodePudding user response:
Select the columns ab_min and cd_min then use 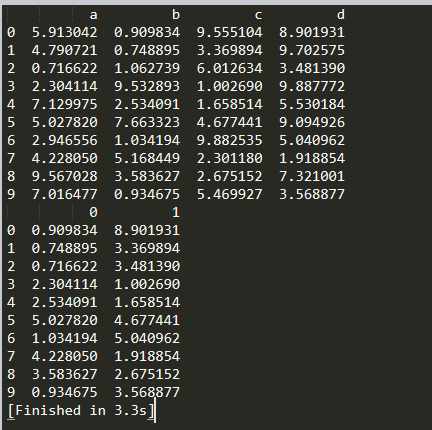
CodePudding user response:
You can use .apply with a lambda function along axis=1:
xdf['minimum'] = xdf.apply(lambda x: [x[['a','b']].min(),x[['c','d']].min()], axis=1)
Result:
>>> xdf
a b c d minimum
0 0.662634 4.166338 8.864823 9.004818 [0.6626341544146663, 8.864822751494284]
1 6.854054 6.163417 6.510728 0.049498 [6.163416966676091, 0.04949754019059838]
2 6.389760 4.462319 2.435369 3.732534 [4.462318678134215, 2.4353686460846893]
3 4.628735 7.571098 1.900726 9.046384 [4.628735362058981, 1.9007255361271058]
4 3.203285 4.364302 2.473973 2.911911 [3.203285015796596, 2.4739732602476727]
5 5.357440 3.166420 9.908758 0.910704 [3.166420385020304, 0.91070444348338]
6 8.120486 6.395869 0.970977 5.278279 [6.395868901095546, 0.9709769503958143]
7 1.574765 7.184971 3.835641 4.495135 [1.574765093192545, 3.835640598199231]
8 8.688497 0.069061 0.771772 8.971878 [0.06906065557899743, 0.7717717844423222]
9 5.455920 2.630342 1.966357 7.374366 [2.6303421168291843, 1.966357159086991]