I am really stuck on this problem.
I have a data frame like in the figure. I have multiple ids with one column value.
I want to build another data frame that only has the distinct id and also the data frame has 4 different numbers of the column "c0" in the existing data frame.
For example, for number 10, we have 2 and 4 and 2. we put 2,2,2,2 and 4, 4, 4,4 and 2,2,2,2 in front of id=10. For the case where we don't have enough data, we put 0 for them. Here is an comprehensive and simple example:
import pandas as pd
import numpy as np
df = pd.DataFrame()
df['id'] = [ 10, 10, 20, 10]
df['c0'] = [ 2, 4, 7,2]
Here is the data frame which I am looking for:
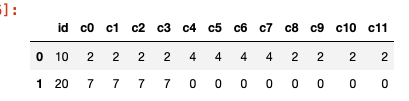
CodePudding user response:
Use pd.Index.repeat as starting point to expand your dataframe then pivot_table to reshape it:
N = 4 # or len(df) ???
out = (
df.reindex(df.index.repeat(N)).assign(col=lambda x: x.groupby('id').cumcount())
.pivot_table('c0', 'id', 'col', fill_value=0)
.add_prefix('c').rename_axis(index=None, columns=None)
)
print(out)
# Output
c0 c1 c2 c3 c4 c5 c6 c7 c8 c9 c10 c11
10 2 2 2 2 4 4 4 4 2 2 2 2
20 7 7 7 7 0 0 0 0 0 0 0 0