I'm doing an exercise for a Python and Data Analysis basic course, but I'm having trouble with pandas' drop_duplicates function. In my working directory I have a csv file with this structure:
name,type,size(B)
bw,.png,94926
ciao,.txt,12
daffodil,.jpg,24657
eclipse,.png,64243
pippo,.odt,8299
song1,.mp3,1087849
song2,.mp3,764176
trump,.jpeg,10195
bw,.png,94926
daffodil,.jpg,24657
eclipse,.png,64243
trump,.jpeg,10195
bw,.png,94926
daffodil,.jpg,24657
eclipse,.png,64243
trump,.jpeg,10195
This is a part of the program where I move files to their folders based on their extension, create / update a recap file with the file data and, finally, try to remove any duplicates rows from the csv:
def move_files_and_update_recap(files, files_dir_path):
with open('recap.csv', 'a', newline='') as recap:
writer = csv.writer(recap)
if("recap.csv" not in work_dir_elements):
writer.writerow(['name', 'type', 'size(B)'])
for file in sorted(files):
# original file path
file_path = os.path.join(files_dir_path, file)
# file name
file_name = os.path.splitext(file)[0]
# file extension
file_extension = os.path.splitext(file)[1]
#file size
file_size = os.path.getsize(file_path)
#file type
file_type = ""
for key, value in file_types.items():
if(file.endswith(tuple(value))): # if the file has a recognizable extension findable in "file_types"
file_type = key
#if file already exists in the specific folder, print an error
if(file in os.listdir(os.path.join(files_dir_path, file_type))):
print("Operation failed: {} already exists in {} folder".format(file, file_type))
else:
# moving file to a specific directory based on its extension
shutil.move(os.path.join(files_dir_path, file), os.path.join(files_dir_path, file_type, file))
# print file info
print("{} type:{} size:{}".format(file_name, file_extension, file_size))
file_data = [file_name, file_extension, str(file_size)] # data info for csv file
writer.writerow(file_data)
df = pd.read_csv('recap.csv')
df.drop_duplicates(inplace=True)
I tried also different settings of the function:
df.drop_duplicates(subset=None, keep=False, inplace=True)
or:
df.drop_duplicates(subset=None, keep="first", inplace=True)
If I print df the result is an indexed dataframe:
name type size(B)
0 bw .png 94926
1 ciao .txt 12
2 daffodil .jpg 24657
3 eclipse .png 64243
4 pippo .odt 8299
5 song1 .mp3 1087849
6 song2 .mp3 764176
7 trump .jpeg 10195
8 bw .png 94926
9 daffodil .jpg 24657
10 eclipse .png 64243
11 trump .jpeg 10195
12 bw .png 94926
13 daffodil .jpg 24657
14 eclipse .png 64243
15 trump .jpeg 10195
If I print the drop_duplicates result the return value is None. Some suggestions on how to fix it?
CodePudding user response:
I think you must be doing something wrong. I have tried to reproduce the whole scenario that you have described but it seems to be working in my case.
Let me share some details
Code to create a dataframe:
import re
import pandas as pd
lines = '''name type size(B)
0 bw .png 94926
1 ciao .txt 12
2 daffodil .jpg 24657
3 eclipse .png 64243
4 pippo .odt 8299
5 song1 .mp3 1087849
6 song2 .mp3 764176
7 trump .jpeg 10195
8 bw .png 94926
9 daffodil .jpg 24657
10 eclipse .png 64243
11 trump .jpeg 10195
12 bw .png 94926
13 daffodil .jpg 24657
14 eclipse .png 64243
15 trump .jpeg 10195'''.splitlines()
columns = lines[0].split()
lines = [re.sub(r'^\d \s ', '', line).strip() for line in lines[1:]]
lines = [{columns[0]:line.split()[0], columns[1]:line.split()[1], columns[2]:line.split()[2]} for line in lines]
df = pd.DataFrame(lines)
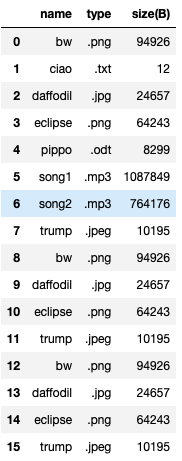
Applied the functions to remove duplicates
Scenario 1:
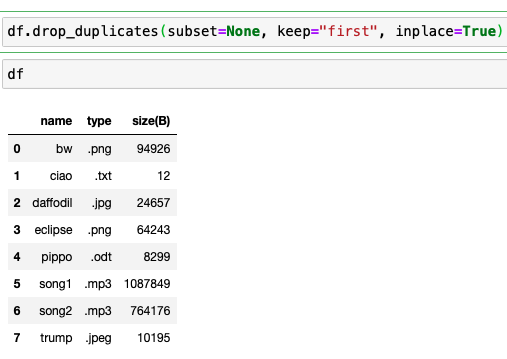
Senario 2:
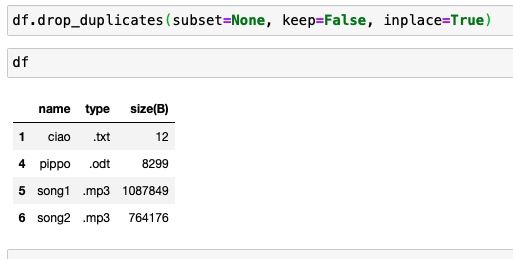
CodePudding user response:
you could try: df = df.drop_duplicates(..params) since setting inplace to true isn't always reliable. this was answered a few times -> like here