I have:
haves = pd.DataFrame({'Product':['R123','R234'],
'Price':[1.18,0.23],
'CS_Medium':[1, 0],
'CS_Small':[0, 1],
'SC_A':[1,0],
'SC_B':[0,1],
'SC_C':[0,0]})
print(haves)

given a list of columns, like so:
list_of_starts_with = ["CS_", "SC_"]
I would like to arrive here:
wants = pd.DataFrame({'Product':['R123','R234'],
'Price':[1.18,0.23],
'CS':['Medium', 'Small'],
'SC':['A', 'B'],})
print(wants)
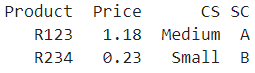
I am aware of wide_to_long but don't think it is applicable here?
CodePudding user response:
We could convert "SC" and "CS" column values to boolean mask to filter the column names; then join it back to the original DataFrame:
msk = haves.columns.str.contains('_')
s = haves.loc[:, msk].astype(bool)
s = s.apply(lambda x: dict(s.columns[x].str.split('_')), axis=1)
out = haves.loc[:, ~msk].join(pd.DataFrame(s.tolist(), index=s.index))
Output:
Product Price CS SC
0 R123 1.18 Medium A
1 R234 0.23 Small B
CodePudding user response:
Based on the list of columns (assuming the starts_with is enough to identify them), it is possible to do the changes in bulk:
def preprocess_column_names(list_of_starts_with, column_names):
"Returns a list of tuples (merged_column_name, options, columns)"
columns_to_transform = []
for starts_with in list_of_starts_with:
len_of_start = len(starts_with)
columns = [col for col in column_names if col.startswith(starts_with)]
options = [col[len_of_start:] for col in columns]
merged_column_name = starts_with[:-1] # Assuming that the last char is not needed
columns_to_transform.append((merged_column_name, options, columns))
return columns_to_transform
def merge_columns(df, merged_column_name, options, columns):
for col, option in zip(columns, options):
df.loc[df[col] == 1, merged_column_name] = option
return df.drop(columns=columns)
def merge_all(df, columns_to_transform):
for merged_column_name, options, columns in columns_to_transform:
df = merge_columns(df, merged_column_name, options, columns)
return df
And to run:
columns_to_transform = preprocess_column_names(list_of_starts_with, haves.columns)
wants = merge_all(haves, columns_to_transform)
If your column names are not surprising (such as Index_ being in list_of_starts_with) the above code should solve the problem with a reasonable performance.
CodePudding user response:
One option is to convert the data to a long form, filter for rows that have a value of 1, then convert back to wide form. We can use pivot_longer from pyjanitor for the wide to long part, and pivot to return to wide form:
# pip install pyjanitor
import pandas as pd
import janitor
( haves
.pivot_longer(index=["Product", "Price"],
names_to=("main", "other"),
names_sep="_")
.query("value==1")
.pivot(index=["Product", "Price"],
columns="main",
values="other")
.rename_axis(columns=None)
.reset_index()
)
Product Price CS SC
0 R123 1.18 Medium A
1 R234 0.23 Small B
You can totally avoid pyjanitor, by tranforming on the columns before reshaping (it still involves wide to long, then long to wide):
index = [col for col in haves
if not col.startswith(tuple(list_of_starts_with))]
temp = haves.set_index(index)
temp.columns = (temp
.columns.str.split("_", expand=True)
.set_names(["main", "other"])
# reshape to get final dataframe
(temp
.stack(["main", "other"])
.loc[lambda df: df == 1]
.reset_index("other")
.drop(columns=0)
.unstack()
.droplevel(0, 1)
.rename_axis(columns=None)
.reset_index()
)
Product Price CS SC
0 R123 1.18 Medium A
1 R234 0.23 Small B