I'm really stuck trying to match the teams in respect to the metropolitan area using the data from two differents dataframes to get the population of the cities for each team. The dataframes looks like this and I wanted a new column in the first that has the population of the cities of that respective team.
I can't even think of a solution using regex, but I've tried this:
for index, row in cities.iterrows():
for index1, row1 in nhl_df.iterrows():
if row['NHL'] in row1['team']:
row1['Population'] = row['Population']
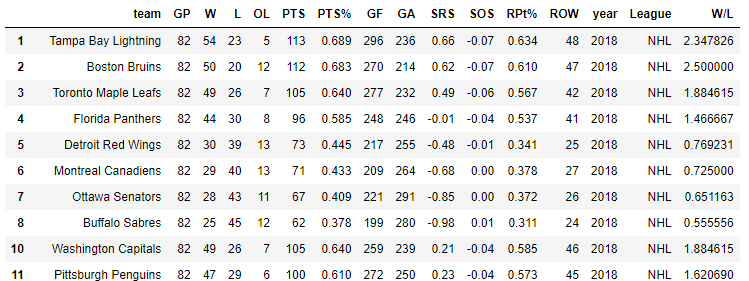
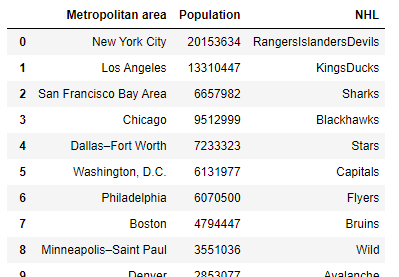
The first dataframe in the images is the "nhl_df" dataframe and the second is the "cities" dataframe.
CodePudding user response:
Please check the following code. Some explanations:
iterrors() is extremely slow. If your data is small than fine, but generally this is less recommended and I suggest you read about itertuples() for example and maybe try it instead.
My general logic was to break the team's name using regex in the cities table (getting a list of word(s) that comprise the team's name). Then, doing the same for 'team' column in nil_df.
If all the elements in the smaller list appears in the bigger list - then it's match and we can then take the population.
For example:
['Kings', 'Ducks] = for cities table ['Los', 'Angeles', 'Kings', 'Ducks'] = for nil_df table
Since the first list is entirely inside the second list = match. Get the population and store in the index location on nil_df.
P.S. - Please keep in mind that there are much better iterations methods out there that outperforms terrors()
for i, r in cities.iterrows():
team_regex = re.findall('[A-Z][^A-Z]*', r['NHL'])
for idx, row in nhl_df.iterrows():
team_split = row['team'].split(" ")
if all(elem in team_split for elem in team_regex):
nhl_df.loc[idx,'Population'] = cities.loc[i,'Population']